Since I've deprecated scenarios, I went through all of my projects and removed any usages of expectations.scenarios. For the most part the conversion was simple; however, I did run into one instance where the scenario contained interleaved expectations.
The following code is an example of a scenario with interleaved expectations.
In the previously linked blog entry I recommend using a clojure assert to replace the interleaved expectations. That solution works, but I found an additional approach that I wanted to share.
When I encountered code similar in structure to the code above, I immediately envisioned writing 3 expectations similar to what you find below.
note: for my contrived example the first two tests could have been written without the let; however, the tests from my codebase could not - and I believe the blog entry is easier to follow if the tests are written in the way above.
While these tests verify the same expectations, the way that they are written doesn't convey to a test maintainer that they relate to each other more than they are related to the other tests within the file. While pondering this complaint, I grouped the tests in the following way more as a joke than anything else.
I would never actually use given simply to group code; however, grouping the code together did cause me to notice that there was a usage of given that would not only keep the code grouped, but it would also allow me to test what I needed with less code.
The following example is very similar in structure to the finished product within my codebase.
The above example verifies everything that the original scenario verified, does not use a scenario, and conveys to a maintainer that related logic is being tested within all three tests - in short: this felt like the right solution.
Wednesday, November 14, 2012
Tuesday, November 13, 2012
Elisp: Duplicate Line
After switching to emacs I quickly noticed that I was missing a simple keystroke for duplicating a line. Yes, I know it's as easy as C-a, C-k, C-y, Enter, C-y. Still, I wanted a keystroke. So, I coded up the following snippet. It's similar to what you'd find elsewhere on the net, but it also moves the cursor to where I've gotten used to it ending up.
Thursday, November 08, 2012
Elisp: Automated Switching Between Clojure Test and Source Files
The majority of the work that I do in emacs is Clojure programming. The Clojure navigation support (M-.) is usually all I need, but one thing that I find myself doing manually fairly often is jumping between tests and source. After suffering manual navigation for a few days, I finally automated the task using the Elisp from this blog entry.
All of my Clojure projects use both Leiningen and expectations; therefore, my directory structures always look similar to what you see below.
Since my projects follow this convention, I'm able to make several assumptions about where the expectations and where the source will actually live. If you don't use expectations, or you follow a slightly different directory structure, you'll want to hack this a bit to follow your conventions.
If you're in a source file, find (and open) the expectations.
If you're in a test file, find (and open) the source.
All of my Clojure projects use both Leiningen and expectations; therefore, my directory structures always look similar to what you see below.
source - /Users/jfields/src/project-name/src/clojure/
tests - /Users/jfields/src/project-name/test/clojure/expectations/
Since my projects follow this convention, I'm able to make several assumptions about where the expectations and where the source will actually live. If you don't use expectations, or you follow a slightly different directory structure, you'll want to hack this a bit to follow your conventions.
If you're in a source file, find (and open) the expectations.
If you're in a test file, find (and open) the source.
Wednesday, November 07, 2012
Elisp: Grep in Clojure Project
Grep'ing within my current project is something I do frequently. It's not much to type, but I do it often enough that I was looking for a keystroke. Most of my projects are Clojure and use Leiningen, thus I'm able to make some pretty safe assumptions. The following snippets allow you to easily grep within your project.
note: both use expand-region to grab the clojure that the cursor is on or immediately after, and grep for whatever was selected.
grep recursively starting at the directory where the project.clj file lives
grep recursively, but allow the user to select the root directory (defaulting to the location of the project.clj file). I often use this one for selecting only the src or test directories of my project.
note: both use expand-region to grab the clojure that the cursor is on or immediately after, and grep for whatever was selected.
grep recursively starting at the directory where the project.clj file lives
grep recursively, but allow the user to select the root directory (defaulting to the location of the project.clj file). I often use this one for selecting only the src or test directories of my project.
Tuesday, November 06, 2012
Clojure: Deprecating expectations.scenarios
I previously mentioned:
Truthfully, I've never liked scenarios - I've always viewed them as a necessary evil. First of all, I hate that you can't mix them with bare expectations - this leads to having 2 files or 2 namespaces in 1 file (or you put everything in a scenario, meh). You either can't see all of your tests at the same time (2 files), or you run the risk of your tests not working correctly with other tools (expectations-mode doesn't like having both namespaces in 1 file). Secondly, I think they lead to sloppy tests.
The second complaint causes me to get on my soap-box about test writing, but never motivated me to do anything. However, as expectations-mode has become more integral to my workflow, the first issue caused me to make a change.
As of 1.4.17 you should be able to write anything that you would usually write in a scenario in a bare expect instead.
I've already published several blog entries that should help if you're interested in migrating your scenarios to bare expectations.
If you were previously using stubbing, your test can be converted in the following way.
There is one type of scenario that I haven't yet addressed, interleaved expectations. I found zero of these types of scenarios in my codebases; however, I'm addressing these types of scenarios here for completeness.
If you run into issues while converting your scenarios, please open an issue on github: https://github.com/jaycfields/expectations/issues?state=open
The functionality in expectations.scenarios was borne out of compromise. I found certain scenarios I wanted to test, but I wasn't sure how to easily test them using what was already available in (bare) expectations. The solution was to add expectations.scenarios, and experiment with various features that make testing as easy as possible.
Truthfully, I've never liked scenarios - I've always viewed them as a necessary evil. First of all, I hate that you can't mix them with bare expectations - this leads to having 2 files or 2 namespaces in 1 file (or you put everything in a scenario, meh). You either can't see all of your tests at the same time (2 files), or you run the risk of your tests not working correctly with other tools (expectations-mode doesn't like having both namespaces in 1 file). Secondly, I think they lead to sloppy tests.
The second complaint causes me to get on my soap-box about test writing, but never motivated me to do anything. However, as expectations-mode has become more integral to my workflow, the first issue caused me to make a change.
As of 1.4.17 you should be able to write anything that you would usually write in a scenario in a bare expect instead.
I've already published several blog entries that should help if you're interested in migrating your scenarios to bare expectations.
- Freezing Time Added To expectations
- Interaction Based Testing Added To expectations
- redef-state Added To expectations
- Using given & expect To Replace scenarios
If you were previously using stubbing, your test can be converted in the following way.
(stubbing [a-fn true] (do-work)) ;;; can now be written as (with-redefs [a-fn (constantly true)] (do-work))A nice side effect of removing stubbing is the reduction of indention if you are using both stubbing and with-redefs. This seems like the right trade-off for me (less indenting, relying on core functions that everyone should know); however, I'm not against adding stubbing again in the future if it becomes a painfully missing feature.
There is one type of scenario that I haven't yet addressed, interleaved expectations. I found zero of these types of scenarios in my codebases; however, I'm addressing these types of scenarios here for completeness.
(scenario (do-work) (expect a b) (do-more-work) (expect c d))Any scenario that has interleaved expectations can be converted in the following way:
(expect c
(do
(do-work)
(assert (= a b))
(do-more-work)
d))
expectations 1.4.17 still has support for scenarios, so you can upgrade and migrate at your own pace. I'll likely leave scenarios in until the point that I change some code that breaks them, then I'll remove them. Of course, if you prefer scenarios, you're welcome to never upgrade, or fork expectations.
If you run into issues while converting your scenarios, please open an issue on github: https://github.com/jaycfields/expectations/issues?state=open
Monday, November 05, 2012
Clojure: Using given & expect To Replace scenarios
The functionality in expectations.scenarios was borne out of compromise. I found certain scenarios I wanted to test, but I wasn't sure how to easily test them using what was already available in (bare) expectations. The solution was to add expectations.scenarios, and experiment with various features that make testing as easy as possible.
Two years later, the features that make sense have migrated back to expectations:
Below is an example of a scenario that ends with multiple expects.
Using given, these scenarios are actually very easy to convert. The given + bare expectation example below tests exactly the same logic.
The test coverage is the same in the second example, but it is important to note that the let will now be executed 3 times instead of 1. This isn't an issue if your tests run quickly, if they don't you may want to revisit the test to determine if it can be written in a different way.
An interesting side-effect occurred while I was converting my scenarios - I found that some of my scenarios could be broken into multiple expectations that were then easier to read and maintain.
For example, the above expectations could be written as the example below.
note: you could simplify even further and remove the given, but that's likely only due to how contrived the test is. Still, the possibility exists that some scenarios will be easily convertible to bare expectations.
Using the technique described here, I've created bare expectations for all of the scenarios in the codebase I'm currently working on - and deleted all references to expectations.scenarios.
Two years later, the features that make sense have migrated back to expectations:
- Freezing Time Added To expectations
- Interaction Based Testing Added To expectations
- redef-state Added To expectations
Below is an example of a scenario that ends with multiple expects.
Using given, these scenarios are actually very easy to convert. The given + bare expectation example below tests exactly the same logic.
The test coverage is the same in the second example, but it is important to note that the let will now be executed 3 times instead of 1. This isn't an issue if your tests run quickly, if they don't you may want to revisit the test to determine if it can be written in a different way.
An interesting side-effect occurred while I was converting my scenarios - I found that some of my scenarios could be broken into multiple expectations that were then easier to read and maintain.
For example, the above expectations could be written as the example below.
note: you could simplify even further and remove the given, but that's likely only due to how contrived the test is. Still, the possibility exists that some scenarios will be easily convertible to bare expectations.
Using the technique described here, I've created bare expectations for all of the scenarios in the codebase I'm currently working on - and deleted all references to expectations.scenarios.
Thursday, November 01, 2012
Clojure: Use expect-let To Share A Value Between expected And actual
Most of the time you can easily divorce the values needed in an expected form and an actual form of an expectation. In those cases, nothing needs to be shared and your test can use a simple bare expect. However, there are times when you need the same value in both the expected and actual forms - and a bare expect doesn't easily provide with a way to accomplish that.
In version 1.4.16 or higher of expectations, you can now use the expect-let macro to let one or more values and reference them in both the expected and actual forms.
Below is a simple example that makes use of expect-let to compare two maps that both have a DateTime.
If possible you should prefer expect, but expect-let gives you another option for the rare cases where you absolutely need to share a value.
In version 1.4.16 or higher of expectations, you can now use the expect-let macro to let one or more values and reference them in both the expected and actual forms.
Below is a simple example that makes use of expect-let to compare two maps that both have a DateTime.
If possible you should prefer expect, but expect-let gives you another option for the rare cases where you absolutely need to share a value.
Clojure: Freezing Time Added To expectations
If you're using expectations and Joda Time, you now have the ability to freeze time in bare expectations (version 1.4.16 and above). The following code demonstrates how you can use the freeze-time macro to set the time, verify anything you need, and allow time to be reset for you.
Under the covers freeze-time is setting the current millis using the DateTime you specify, running your code and resetting the current millis in a finally. As a result, after your code finishes executing, even if finishing involves throwing an exception, the millis of Joda Time will be set back to working as you'd expect.
The freeze-time macro can be used in both the expected and actual forms, and can be nested if you need to set the time multiple times within a single expectation.
Under the covers freeze-time is setting the current millis using the DateTime you specify, running your code and resetting the current millis in a finally. As a result, after your code finishes executing, even if finishing involves throwing an exception, the millis of Joda Time will be set back to working as you'd expect.
The freeze-time macro can be used in both the expected and actual forms, and can be nested if you need to set the time multiple times within a single expectation.
Clojure: Interaction Based Testing Added To expectations
The vast majority of testing I do these days is state-based; however, there are times when I need to test an interaction (e.g. writing to a file or printing to standard out). The ability to test interactions has been in expectations.scenarios for quite awhile, but there isn't any reason that you need a scenario to test an interaction - so, as of version 1.4.16, you also have the ability to test interactions with bare expectations.
The following test shows how you can specify an expected interaction. This test passes.
Writing the test should be straightforward - expect the interaction and then call the code that causes the interaction to happen.
As I was adding this behavior I enhanced the error reporting. Below you can find a failing test and the output that is produced.
As you can see, all three calls to the 'one' function are reported. If the number of args used to call 'one' are of the same size as the expected args, each arg is compared in detail; otherwise the two lists are compared in detail (but the elements are not).
As you can see in this failure the first argument, "hello", matches.
That's it. Hopefully these interaction tests follow the principle of least surprise, and are easy for everyone to use.
The following test shows how you can specify an expected interaction. This test passes.
Writing the test should be straightforward - expect the interaction and then call the code that causes the interaction to happen.
As I was adding this behavior I enhanced the error reporting. Below you can find a failing test and the output that is produced.
As you can see, all three calls to the 'one' function are reported. If the number of args used to call 'one' are of the same size as the expected args, each arg is compared in detail; otherwise the two lists are compared in detail (but the elements are not).
As you can see in this failure the first argument, "hello", matches.
; got: (one "hello" {2 3, :a 1})
; arg1: matches
; expected arg2: {:a :b, :c {:ff :gg, :dd :ee}}
; actual arg2: {2 3, :a 1}
; 2 with val 3 is in actual, but not in expected
; :c {:dd with val :ee is in expected, but not in actual
; :c {:ff with val :gg is in expected, but not in actual
; :a expected: :b
; was: 1
Anytime an argument matches expectations will simply print "matches". You can also specify :anything as an argument, to ignore that argument and always 'match'. The following test shows an example of matching the second argument, while the first argument is no longer matching.
That's it. Hopefully these interaction tests follow the principle of least surprise, and are easy for everyone to use.
Wednesday, October 31, 2012
Clojure: redef-state Added To expectations
When testing functions that reference some state (atom, ref, or agent), it's nice to be able to quickly replace the value of the state in the context of the test. When your function only interacts with one piece of state, a simple call to with-redefs will do the trick. However, there are times when the function that you're calling updates many different pieces of state, and you'd like to be able to redef all of them with one call. The expectations testing framework (v 1.4.16 and above) provides you the ability to redef all atoms, refs, and agents in a namespace with one call to redef-state.
(this same feature existed in expectation.scenarios as 'localize-state')
Let's take a look at the following contrived namespace
In the above namespace we have two atoms that are both updated when you process an update. Testing that the atoms are updated is fairly simple, which the tests below demonstrate.
Unfortunately, these tests will not both pass, as they both update the same atom. We could clean up at the end of each test, but it's usually cleaner to simply redef the atoms in the context of the test. The tests below use with-redefs to ensure that the state is only manipulated in the context of the tests.
At this point the tests all pass. This solution works fine, but expectations gives you the ability to trim a bit of code and simply specify the namespace instead. The following tests specify the namespace and let expectations take care of the rest.
That's it. Now all atoms, refs, and agents that are defined in the 'blog' namespace will be redefined within the context of the (redef-state) call. It's also important to note that redef-state can take as many namespaces as you'd like to specify in the first arg vector.
(this same feature existed in expectation.scenarios as 'localize-state')
Let's take a look at the following contrived namespace
In the above namespace we have two atoms that are both updated when you process an update. Testing that the atoms are updated is fairly simple, which the tests below demonstrate.
Unfortunately, these tests will not both pass, as they both update the same atom. We could clean up at the end of each test, but it's usually cleaner to simply redef the atoms in the context of the test. The tests below use with-redefs to ensure that the state is only manipulated in the context of the tests.
At this point the tests all pass. This solution works fine, but expectations gives you the ability to trim a bit of code and simply specify the namespace instead. The following tests specify the namespace and let expectations take care of the rest.
That's it. Now all atoms, refs, and agents that are defined in the 'blog' namespace will be redefined within the context of the (redef-state) call. It's also important to note that redef-state can take as many namespaces as you'd like to specify in the first arg vector.
Tuesday, October 09, 2012
Java: Add A Println To A 3rd-Party Class Using IntelliJ's Debugger
When I'm working with 3rd party Java code (e.g. joda.time.DateTime) and I want to inspect values that are created within that code, I generally set a breakpoint in IntelliJ and take a look around. This works the vast majority of the time; however, there are times when this approach isn't an option. For example, if stopping your application changes the state of what you're looking at, or if stopping the application causes your breakpoint to fire repeatedly in irrelevant situations, then you'll probably want another solution for looking around 3rd party code.
It turns out, IntelliJ gives you the ability to inspect values within 3rd party code - without needing to stop the application at a breakpoint. The following code uses the 3rd party library joda-time, and is simply printing the current time to the console.
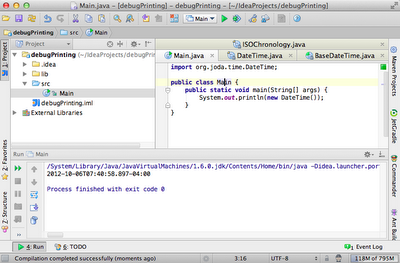
note: this code could simply use a breakpoint if you wanted to inspect some 3rd party code, but I didn't see the value in creating a more complicated example.
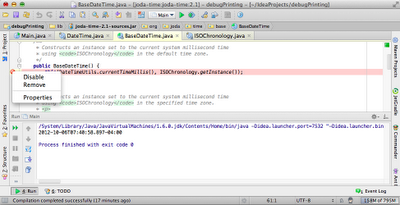
In the example, we're calling the constructor of DateTime, which simply delegates to the BaseDateTime constructor, which can be seen in the following screenshot.

So, we're looking at joda-time code that we can't edit, but our task is to get the value of DateTimeUtils.currentTimeMillis() and ISOChronology.getInstance() without stopping the application. The solution is to add a breakpoint, but do a bit of customization.
In the following screenshot we've added a breakpoint to the line that contains the values we're interested in and we're right clicking on the breakpoint, which will allow us to edit the properties of the breakpoint.
When we open the properties of a breakpoint, they will look something like the following screenshot.
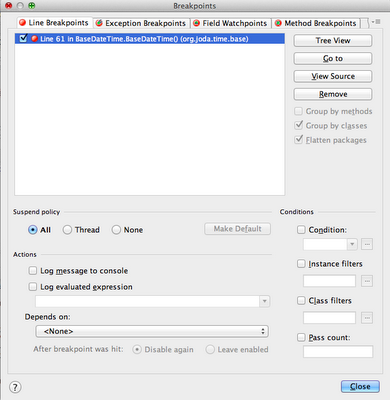
In the properties window you'll want to set Suspend policy to 'None', and you'll want to set something in Log evaluated expression. In my properties window I've set the following expression:

At that point you close the properties pop-up and run your app once again (in Debug mode).

As you can see from the output, both the millis and the ISOChronology were printed to the console, and the application processing was never broken (it simply ended as expected).
That's it - now you can println in code you don't own to your heart's content.
It turns out, IntelliJ gives you the ability to inspect values within 3rd party code - without needing to stop the application at a breakpoint. The following code uses the 3rd party library joda-time, and is simply printing the current time to the console.

note: this code could simply use a breakpoint if you wanted to inspect some 3rd party code, but I didn't see the value in creating a more complicated example.
In the example, we're calling the constructor of DateTime, which simply delegates to the BaseDateTime constructor, which can be seen in the following screenshot.

So, we're looking at joda-time code that we can't edit, but our task is to get the value of DateTimeUtils.currentTimeMillis() and ISOChronology.getInstance() without stopping the application. The solution is to add a breakpoint, but do a bit of customization.
In the following screenshot we've added a breakpoint to the line that contains the values we're interested in and we're right clicking on the breakpoint, which will allow us to edit the properties of the breakpoint.

When we open the properties of a breakpoint, they will look something like the following screenshot.

In the properties window you'll want to set Suspend policy to 'None', and you'll want to set something in Log evaluated expression. In my properties window I've set the following expression:
System.out.println(DateTimeUtils.currentTimeMillis() + ", " + ISOChronology.getInstance()); - though, you can't see the full snippet in the screenshot.

At that point you close the properties pop-up and run your app once again (in Debug mode).

As you can see from the output, both the millis and the ISOChronology were printed to the console, and the application processing was never broken (it simply ended as expected).
That's it - now you can println in code you don't own to your heart's content.
Wednesday, October 03, 2012
clojure: lein tar
A co-worker recently asked how I package and deploy my clojure code. There's nothing special about the code, but I'm making it available here for anyone who wants to cut and paste. Deploy is the easy part - scp a tar to the prod box. Building the tar is very easy as well. I've run this on a few different linux distros without issue, but YMMV. Without further ado.
I'm sure there are easier ways, and I know I could do it programically - but this works and is easy to maintain. That's good enough for me.
I'm sure there are easier ways, and I know I could do it programically - but this works and is easy to maintain. That's good enough for me.
Tuesday, October 02, 2012
Clojure: Avoiding Anonymous Functions

Next, I went through several of the exercises on 4clojure.org and it opened my eyes to the sheer number of functions that I should have, but still didn't know. 4clojure.org helped me learn how to use many of the functions from the standard lib, but it also taught me a greater lesson: any data transformation I want to do can likely either be accomplished with a single function of clojure.core or by combining a few functions from clojure.core.
The following code has an example input and shows the desired output.
There are many ways to solve this problem, but when I began with Clojure I solved it with a reduce. In general, anytime I was transforming a seq to a map, I thought reduce was the right choice. The following example shows how to transform the data using a reduce
That works perfectly well and it's not a lot of code, but it's custom code. You can't know what the input is, look at the reduce, and know what the output is. You have to jump in the source to see what the transformation actually is.
You can solve this problem with an anonymous function, as the example below shows.
This solution isn't much code, but it's doing several things and requiring you to keep many things on your mental stack at the same time - what does the element look like, destructuring, the form of the result, the initial value, etc. It's not that tough to write, but it can be a bit tough to read when you come back to it 6 months later. Below is another solution, using only functions defined in clojure.core.
The above solution is more characters, but I consider it to be superior for two reasons:
- Only clojure.core functions are used, so I am able to read the code without having to look elsewhere for implementation or documentation (and maintainers should be able to do the same).
- The transformation happens in distinct and easy to understand steps.
If the learning opportunity did not exist, I may feel differently; however, I currently feel much more comfortable with update-in than I do with using juxt, and to a lesser extent (partial apply hash-map) & (apply merge concat). If you found the solution I prefer harder to follow, then I suspect you may be in the same boat as me. If you were easily able to read and follow both solutions, it probably makes sense for you to simply do what you prefer. However, if you choose to define your own function I do believe you're leaving behind something that's harder to digest than a string of distinct steps that only use functions found in clojure.core.
Regardless of language, I believe that you should know the standard library inside and out. Time and time again (in Clojure) I've solved a problem with an anonymous function, only to later find that the standard library already defined exactly what I needed. A few examples from memory: find (select-keys with 1 key), keep (filter + remove nil?), map-indexed (map f coll (range)), mapcat (concat (map)). After making this mistake enough times, I devised a plan to avoid this situation in the future while also forcing myself to become more familiar with the standard library.
The plan is simple: when transforming data, don't use (fn) or #(), and only define a function when it cannot be done with -> or ->> and clojure.core.
My preferred solution (above) is a simple example of using threading and clojure.core to solve a problem without #() or (fn). This works for 90% of the transformation problems I encounter; however, there are times that I need to define a function. For example, I recently needed to take an initial value, pass it to reduce, then pass the result of the reduce as the initial value to another reduce. The initial value is the 2nd of reduce's 3 args, thus it cannot easily be threaded. In that situation, I find it appropriate to simply define my own function. Still, at least 90% of the time I can find a solution by combining existing clojure.core functions (often by using comp, juxt, or partial).
Here's another simple example: Given a list of maps, filter maps where :current-city is "new york"
Once you've made this step, you may start asking yourself: am I doing something unique, or am I doing something that's common enough to be somewhere in the standard library. More often than I expected, the answer is - yes, there's already a fn in the standard library. In this case, we can use clojure.set/join to join on the current city, thus removing our undesired data.
Asking the question, "this doesn't seem unique - shouldn't there be a fn in the standard library that does this?", is what led me to clojure.set/project, find and so many other functions. Now, when I look through old code, I find myself shaking my head and wishing I'd started down this path even earlier. Clojure makes it easy to define your own functions that quickly solve problems, but using what's already in clojure.core makes your code significantly easier for others to follow - learning the standard library inside and out is worth the effort in the long term.
Thursday, September 27, 2012
Clojure: Refactoring From Thread Last (->>) To Thread First (->)
I use ->> (thread-last) and -> (thread-first) very often. When I'm transforming data I find it easy to break things down mentally by taking small, specific steps, and I find that -> & ->> allow me to easily express my steps.
Let's begin with a (very contrived) example. Let's assume we have user data and we need a list of all users in "new york", grouped by their employer, and iff their employer is "drw.com" then we only want their name - otherwise we want all of the user's data. In terms of the input and the desired output, below is what we have and what we're looking for.
A solution that uses ->> can be found below.
The above example is very likely the first solution I would create. I go about solving the problem step by step, and if the first step takes my collection as the last argument then I will often begin by using ->>. However, after the solution is functional I will almost always refactor to -> if any of my "steps" do not take the result of the previous step as the last argument. I strongly dislike the above solution - using an anonymous function to make update-in usable with a thread-last feels wrong and is harder for me to parse (when compared with the alternatives found below).
The above solution could be refactored to the following solution
This solution is dry, but it also groups two of my three steps together, while leaving the other step at another level. I expect many people to prefer this solution, but it's not the one that I like the best.
The following solution is how I like to refactor from ->> to ->
My preferred solution has an "extra" thread-last, but it allows me to keep everything on the same level. By keeping everything on the same level, I'm able to easily look at the code and reason about what it's doing. I know that each step is an isolated transformation and I feel freed from keeping a mental stack of what's going on in the other steps.
Let's begin with a (very contrived) example. Let's assume we have user data and we need a list of all users in "new york", grouped by their employer, and iff their employer is "drw.com" then we only want their name - otherwise we want all of the user's data. In terms of the input and the desired output, below is what we have and what we're looking for.
A solution that uses ->> can be found below.
The above example is very likely the first solution I would create. I go about solving the problem step by step, and if the first step takes my collection as the last argument then I will often begin by using ->>. However, after the solution is functional I will almost always refactor to -> if any of my "steps" do not take the result of the previous step as the last argument. I strongly dislike the above solution - using an anonymous function to make update-in usable with a thread-last feels wrong and is harder for me to parse (when compared with the alternatives found below).
The above solution could be refactored to the following solution
This solution is dry, but it also groups two of my three steps together, while leaving the other step at another level. I expect many people to prefer this solution, but it's not the one that I like the best.
The following solution is how I like to refactor from ->> to ->
My preferred solution has an "extra" thread-last, but it allows me to keep everything on the same level. By keeping everything on the same level, I'm able to easily look at the code and reason about what it's doing. I know that each step is an isolated transformation and I feel freed from keeping a mental stack of what's going on in the other steps.
Tuesday, September 25, 2012
Replacing Common Code With clojure.set Function Calls
If you've written a fair amount of Clojure code and aren't familiar with clojure.set, then chances are you've probably reinvented a few functions that are already available in the standard library. In this blog post I'll give a few examples of commonly written code, and I'll show the clojure.set functions that already do everything you need.
Removing elements from a collection is a very common programming task. Sometimes the collection will need to be a vector or a list, and removing an element from the collection will look similar to the example below.
If you're starting with sets, you'll probably get a performance gain by using clojure.set/difference, and if you're going to need a set returned it's less code and likely more performant to use clojure.set/difference rather than calling clojure.core/set on the results of clojure.core/remove.
clojure.set/difference is simple to use - from the docs
Transforming data in clojure is something I do very often. On many occasions I've had a list of maps and I wanted them indexed by 1 or more values. This is fairly easy to do with reduce and update-in, as the example below demonstrates.
Another common case while working with collections is finding the elements that are in both collections. Since sets are functions (and can be used a predicates), finding common elements is as simple as the following clojure.
In a codebase I was once working on I stumbled upon the following code, which inverts a map.
Another common task I find myself doing while working with clojure is trimming data sets. The following code maps over a list of employees and filters out the employer information.
The rename and rename-keys functions of clojure.set are very similar, and they can both be helpful when you're passing around data-structures that are similar and simply require a few renames to play nicely with existing code.
Below are a few simple examples of how to get things done without rename and rename-keys.
If you've gotten this far, I'll assume you already understand how to use filter. The clojure.set namespace has a function that's very similar to filter, but it returns a set. If you don't need a set, you're better off sticking with filter; however, if you're working with sets, you might save yourself a few keystrokes and microseconds by using clojure.set/select instead.
Below is a the documentation and an example.
The clojure.set/subset? and clojure.set/superset? functions are also functions that are straightforward to use, and probably don't benefit from an example of how to create the same results on your own. However, I will provide the docs and 2 brief examples of their usage.
The final function I will document is clojure.set/union. If you needed a list of the unique elements resulting from combining 2 or more lists, you could get the job done with a combination of concat, reduce, and/or set. The example below shows how to do things without using the set function or a set data-structure. note: Using a set would likely be both more efficient and more readable. This example is designed to show that you could do things without sets, but I do not recommend that you code in this way.
The clojure.set namespace does define one additional function, clojure.set/join. To be honest, I haven't used join in production and I don't believe that I'm writing my own inferior versions within my codebases. So, I don't have an example for you, but I do like the examples on clojuredocs.org and I would encourage you to go check them out: http://clojuredocs.org/clojure_core/1.2.0/clojure.set/join
Removing elements from a collection is a very common programming task. Sometimes the collection will need to be a vector or a list, and removing an element from the collection will look similar to the example below.
user=> (remove #{1 2} [1 2 3 4 3 2 1])
(3 4 3)
In the cases where you're starting with a list and you want to return a seq, remove is a good solution. However, you may also find yourself starting with a set or looking to return a set.
If you're starting with sets, you'll probably get a performance gain by using clojure.set/difference, and if you're going to need a set returned it's less code and likely more performant to use clojure.set/difference rather than calling clojure.core/set on the results of clojure.core/remove.
clojure.set/difference is simple to use - from the docs
Usage: (difference s1)
(difference s1 s2)
(difference s1 s2 & sets)
Return a set that is the first set without elements of the remaining sets
A simple example of using clojure.set/difference can be found below.
user=> (clojure.set/difference #{1 2 3 4 5} #{1 2} #{3})
#{4 5}
Transforming data in clojure is something I do very often. On many occasions I've had a list of maps and I wanted them indexed by 1 or more values. This is fairly easy to do with reduce and update-in, as the example below demonstrates.
user=> (def jay {:name "jay fields" :employer "drw"})
#'user/jay
user=> (def mike {:name "mike jones" :employer "forward"})
#'user/mike
user=> (def john {:name "john dydo" :employer "drw"})
#'user/john
user=> (reduce #(update-in %1 [{:employer (:employer %2)}] conj %2) {} [jay mike john])
{{:employer "forward"} ({:name "mike jones", :employer "forward"}),
{:employer "drw"} ({:name "john dydo", :employer "drw"}
{:name "jay fields", :employer "drw"})}
The reduce + update-in combo is a good one, but clojure.set/index is even better - since it's both more concise and doesn't require you to define an anonymous function.
clojure.set/index is also very straightforward to use - from the docs
Usage: (index xrel ks)
Returns a map of the distinct values of ks in the xrel mapped to a set
of the maps in xrel with the corresponding values of ks.
The example below demonstrates how you can get very similar results to what is above by using clojure.set/index.
user=> (clojure.set/index [jay mike john] [:employer])
{{:employer "forward"} #{{:name "mike jones", :employer "forward"}},
{:employer "drw"} #{{:name "john dydo", :employer "drw"}
{:name "jay fields", :employer "drw"}}}
It is worth noting that the reduce + update-in example has seqs as values and can contain duplicates, and the clojure.set/index example has sets as values and will not contain duplicates. In practice, this has never been an issue for me.
Another common case while working with collections is finding the elements that are in both collections. Since sets are functions (and can be used a predicates), finding common elements is as simple as the following clojure.
user=> (filter (set [1 2 3]) [2 3 4]) (2 3)Similar to the clojure.set/difference example, if you have lists or vectors in and you want a seq out, you may want to stick to using filter. However, if you are already working with sets or you can easily convert to sets, you'll probably want to take a look at clojure.set/intersection.
Usage: (intersection s1)
(intersection s1 s2)
(intersection s1 s2 & sets)
Return a set that is the intersection of the input sets
To get results similar to the above example, simply call clojure.set/intersection in a similar way to the example below.
user=> (clojure.set/intersection #{1 2 3} #{2 3 4})
#{2 3}
In a codebase I was once working on I stumbled upon the following code, which inverts a map.
user=> (reduce #(assoc %1 (val %2) (key %2)) {} {1 :one 2 :two 3 :three})
{:three 3, :two 2, :one 1}
The code is simple enough, but a single function call is always preferable.
The name of the function should be self-explanatory; however, an example is presented below for completeness.Usage: (map-invert m) Returns the map with the vals mapped to the keys.
user=> (clojure.set/map-invert {1 :one 2 :two 3 :three})
{:three 3, :two 2, :one 1}
Another common task I find myself doing while working with clojure is trimming data sets. The following code maps over a list of employees and filters out the employer information.
user=> (def jay {:fname "jay" :lname "fields" :employer "drw"})
#'user/jay
user=> (def mike {:fname "mike" :lname "jones" :employer "forward"})
#'user/mike
user=> (def john {:fname "john" :lname "dydo" :employer "drw"})
#'user/john
user=> (map #(select-keys %1 [:fname :lname]) [jay mike john])
({:lname "fields", :fname "jay"}
{:lname "jones", :fname "mike"}
{:lname "dydo", :fname "john"})
The combination of map + select-keys gets the job done, but clojure.set gives us with one function, clojure.set/project, that provides us with virtually the same result - using less code.
The example below demonstrates the similarity in functionality.Usage: (project xrel ks) Returns a rel of the elements of xrel with only the keys in ks
user=> (clojure.set/project [jay mike john] [:fname :lname])
#{{:lname "fields", :fname "jay"}
{:lname "dydo", :fname "john"}
{:lname "jones", :fname "mike"}}
Similar to clojure.set/index, you'll want to take note of the result being a set and not a list, and just like clojure.set/index, this isn't something that ends up causing a problem in practice.
The rename and rename-keys functions of clojure.set are very similar, and they can both be helpful when you're passing around data-structures that are similar and simply require a few renames to play nicely with existing code.
Below are a few simple examples of how to get things done without rename and rename-keys.
user=> (def jay {:fname "jay" :lname "fields" :employer "drw"})
#'user/jay
user=> (def mike {:fname "mike" :lname "jones" :employer "forward"})
#'user/mike
user=> (def john {:fname "john" :lname "dydo" :employer "drw"})
#'user/john
user=> (map
(fn [{:keys [fname lname] :as m}]
(-> m
(assoc :first-name fname :last-name lname)
(dissoc :fname :lname)))
[jay mike john])
({:last-name "fields", :first-name "jay", :employer "drw"}
{:last-name "jones", :first-name "mike", :employer "forward"}
{:last-name "dydo", :first-name "john", :employer "drw"})
user=> (reduce #(assoc %1 ({1 "one" 2 "two"} (key %2)) (val %2)) {} {1 :one 2 :two})
{"two" :two, "one" :one}
The rename & rename-keys functions are very straightforward, and you can find their documentation and example usages below.
Usage: (rename xrel kmap) Returns a rel of the maps in xrel with the keys in kmap renamed to the vals in kmap Usage: (rename-keys map kmap) Returns the map with the keys in kmap renamed to the vals in kmap
user=> (clojure.set/rename [jay mike john] {:fname :first-name :lname :last-name})
#{{:last-name "jones", :first-name "mike", :employer "forward"}
{:last-name "dydo", :first-name "john", :employer "drw"}
{:last-name "fields", :first-name "jay", :employer "drw"}}
user=> (clojure.set/rename-keys {1 :one 2 :two} {1 "one" 2 "two"})
{"two" :two, "one" :one}
If you've gotten this far, I'll assume you already understand how to use filter. The clojure.set namespace has a function that's very similar to filter, but it returns a set. If you don't need a set, you're better off sticking with filter; however, if you're working with sets, you might save yourself a few keystrokes and microseconds by using clojure.set/select instead.
Below is a the documentation and an example.
Usage: (select pred xset) Returns a set of the elements for which pred is true
user=> (clojure.set/select odd? #{1 2 3 4})
#{1 3}
The clojure.set/subset? and clojure.set/superset? functions are also functions that are straightforward to use, and probably don't benefit from an example of how to create the same results on your own. However, I will provide the docs and 2 brief examples of their usage.
Usage: (subset? set1 set2) Is set1 a subset of set2? Usage: (superset? set1 set2) Is set1 a superset of set2?
user=> (clojure.set/superset? #{1 2 3} #{2 3})
true
user=> (clojure.set/subset? #{1 2} #{1 2 3})
true
The final function I will document is clojure.set/union. If you needed a list of the unique elements resulting from combining 2 or more lists, you could get the job done with a combination of concat, reduce, and/or set. The example below shows how to do things without using the set function or a set data-structure. note: Using a set would likely be both more efficient and more readable. This example is designed to show that you could do things without sets, but I do not recommend that you code in this way.
(reduce #(if (some (partial = %2) %1) %1 (conj %1 %2)) [] (concat [1 2 1] [2 4 3 1])) [1 2 4 3]Truthfully, I don't tend to think about 'union' unless I'm already thinking about sets. In Clojure, clojure.set/union is defined to take multiple sets and return the union of each of those sets (as you'd expect).
Usage: (union)
(union s1)
(union s1 s2)
(union s1 s2 & sets)
Return a set that is the union of the input sets
Finally, the example below shows the union function in action.
user=> (clojure.set/union #{1 2} #{2 4 3 1})
#{1 2 3 4}
The clojure.set namespace does define one additional function, clojure.set/join. To be honest, I haven't used join in production and I don't believe that I'm writing my own inferior versions within my codebases. So, I don't have an example for you, but I do like the examples on clojuredocs.org and I would encourage you to go check them out: http://clojuredocs.org/clojure_core/1.2.0/clojure.set/join
Monday, September 17, 2012
emacs lisp: removing a lamba hook
disclaimer: I know almost nothing about emacs lisp, so please forgive any mistakes or incorrect assumptions.
I've been using Clojure for over 4 years at this point, but it's generally been on projects that are mostly Java with a few small components in Clojure. Given that context my teammates preferred that we stick with IntelliJ; however, things have recently changed and the emacs journey has begun.
Taking emacs from 'factory settings' to 'impressive' for me was as easy as getting started with emacs-live.

I get that people like rainbow-delimeters, and I would never try to convince you not to use them - they're just not for me, and I needed to find out how to get rid of them.
Emacs Live adds rainbow-delimiters in two different ways. The following code shows how Emacs Live uses add-hook to enable rainbow delimiters for scheme, emacs-lisp, & lisp.
The next snippet of code is how Emacs Live adds rainbow delimiters (& a few other things) to clojure-mode.
Finding a solution wasn't very hard. The first thing I did was try to get a list of the functions that will be fired by the hook. This is as simple as printing, as the following code shows.
Is this fragile? You bet. If things change in Emacs Live, I'll need to mirror those changes in my .emacs-live.el - which is why it's recommended that you don't rely on ordering when adding and removing hooks. However, given the situation, this seems like a pragmatic solution.
Feedback definitely welcome.
I've been using Clojure for over 4 years at this point, but it's generally been on projects that are mostly Java with a few small components in Clojure. Given that context my teammates preferred that we stick with IntelliJ; however, things have recently changed and the emacs journey has begun.
Taking emacs from 'factory settings' to 'impressive' for me was as easy as getting started with emacs-live.
Emacs Live can be summarized as:Indeed, Emacs Live does structure your config nicely; however, in it's own words: Emacs Live is also an opinionated set of defaults. I like all of the defaults... except one: rainbow-delimitersa nice structured approach to organising your Emacs config
modular in that functionality is organised by discrete packs

I get that people like rainbow-delimeters, and I would never try to convince you not to use them - they're just not for me, and I needed to find out how to get rid of them.
Emacs Live adds rainbow-delimiters in two different ways. The following code shows how Emacs Live uses add-hook to enable rainbow delimiters for scheme, emacs-lisp, & lisp.
(dolist (x '(scheme emacs-lisp lisp))
(add-hook
(intern (concat (symbol-name x) "-mode-hook"))
'rainbow-delimiters-mode))
The code required to remove rainbow-delimiters from scheme, emacs-lisp, & lisp is very straightforward, and can be found below.
(dolist (x '(scheme emacs-lisp lisp))
(remove-hook
(intern (concat (symbol-name x) "-mode-hook"))
'rainbow-delimiters-mode))
As you can see, replacing add-hook with remove-hook will remove the hook that Emacs Live added for me. Since Emacs Live loads my personal settings last, my remove should successfully work every time. It's a best practice that you create hooks that can be run in any order - and this change is obviously order specific; however, I can't think of a way to follow the hook best practice without hacking the emacs-live checkout. Therefore, it seems like this solution is the most pragmatic.The next snippet of code is how Emacs Live adds rainbow delimiters (& a few other things) to clojure-mode.
(add-hook 'clojure-mode-hook
(lambda ()
(enable-paredit-mode)
(rainbow-delimiters-mode)
(add-to-list 'ac-sources 'ac-source-yasnippet)
(setq buffer-save-without-query t)))
The previous hook was easy to remove, since I knew exactly what function I needed to remove. This hook is more of a problem, since it's anonymous. Additionally, this function is defined within Emacs Live code, so simply changing it to a named function isn't an option (since I don't want to modify the emacs-live checkout).Finding a solution wasn't very hard. The first thing I did was try to get a list of the functions that will be fired by the hook. This is as simple as printing, as the following code shows.
(print clojure-mode-hook)I put that simple print statement in my .emacs-live.el, restarted emacs, went to the *Messages* buffer, and found the following line printed out.
((lambda nil
(enable-paredit-mode)
(rainbow-delimiters-mode)
(add-to-list (quote ac-sources) (quote ac-source-yasnippet))
(setq buffer-save-without-query t)))
As you can see, clojure-mode-hook has a list of the functions that have been added via add-hook. With this information, I added the following code, which first removes the existing hook and then adds a new anonymous function with everything previously specified - sans rainbow-delimiters.
(remove-hook 'clojure-mode-hook (first clojure-mode-hook))
(add-hook 'clojure-mode-hook
(lambda ()
(enable-paredit-mode)
(add-to-list 'ac-sources 'ac-source-yasnippet)
(setq buffer-save-without-query t)))
The above snippet removes my unwanted lambda hook and adds a new hook with everything I do want.Is this fragile? You bet. If things change in Emacs Live, I'll need to mirror those changes in my .emacs-live.el - which is why it's recommended that you don't rely on ordering when adding and removing hooks. However, given the situation, this seems like a pragmatic solution.
Feedback definitely welcome.
Tuesday, August 28, 2012
8 Linux Commands Every Developer Should Know
Every developer, at some point in their career, will find themselves looking for some information on a Linux* box. I don't claim to be an expert, in fact, I claim to be very under-skilled when it comes to linux command line mastery. However, with the following 8 commands I can get pretty much anything I need, done.
note: There are extensive documents on each of the following commands. This blog post is not meant to show the exhaustive features of any of the commands. Instead, this is a blog post that shows my most common usages of my most commonly used commands. If you don't know linux commands well, and you find yourself needing to grab some data, this blog post might give you a bit of guidance.
Let's start with some sample documents. Let's assume that I have 2 files showing orders that are being placed with a third party and the responses the third party sends.
sort
grep
Now that we've sent the order details on to refunds, we also want to send the daily totals of sales and refunds on to the accounting team. They've asked for each line item for PofEAA, but they only care about the quantity and price. What we need to do is cut out everything we don't care about.
cut
Using cut is helpful in tracking down problems, but if you're generating an output file you'll often want something more complicated. Let's assume that accounting also needs to know the order ids for building some type of reference documentation. We can get the information using cut, but the accounting team wants the order id to be at the end of the line, and surrounded in single quotes. (for the record, you might be able to do this with cut, I've never tried)
sed
Once we've captured the data we need, we can use \1 & \2 to reorder and output the data in our desired format. We also include the requested double quotes, and add our own comma to keep our format consistent. Finally, we use cut to remove the superfluous data.
Now you're in trouble. You've demonstrated that you can slice up a log file in fairly short order, and the CIO needs a quick report of the total number of book transactions broken down by book.
uniq
The following example shows how to grep for only book related transactions, cut unnecessary information, and get a counted & unique list of each line.
find
Along the same lines, once you find a file you need, you're not always going to know what's in it and how you want to slice it up. Piping the output to standard out works fine when the output is short; however, when there's a bit more data than what fits on a screen, you'll probably want to pipe the output to less.
less
The linux command line is rich, and someone intimidating. However, with the previous 8 commands, you should be able to get quite a few log slicing tasks completed - without having to drop to your favorite scripting language.
* okay, possibly Unix, that's not the point
note: There are extensive documents on each of the following commands. This blog post is not meant to show the exhaustive features of any of the commands. Instead, this is a blog post that shows my most common usages of my most commonly used commands. If you don't know linux commands well, and you find yourself needing to grab some data, this blog post might give you a bit of guidance.
Let's start with some sample documents. Let's assume that I have 2 files showing orders that are being placed with a third party and the responses the third party sends.
order.out.logcat
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
order.in.log
8:22:20 111, Order Complete
8:23:50 112, Order sent to fulfillment
8:24:20 113, Refund sent to processing
cat - concatenate files and print on the standard outputThe cat command is simple, as the following example shows.
jfields$ cat order.out.log 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99As the description shows, you can also use it to concatenate multiple files.
jfields$ cat order.* 8:22:20 111, Order Complete 8:23:50 112, Order sent to fulfillment 8:24:20 113, Refund sent to processing 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99If I wanted to view my log files I can concatenate them and print them to standard out, as the example above shows. That's cool, but things could be a bit more readable.
sort
sort - sort lines of text filesUsing sort is an obvious choice here.
jfields$ cat order.* | sort 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:22:20 111, Order Complete 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99 8:23:50 112, Order sent to fulfillment 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:24:20 113, Refund sent to processingAs the example above shows, my data is now sorted. With small sample files, you can probably deal with reading the entire file. However, any real production log is likely to have plenty of lines that you don't care about. You're going to want a way to filter the results of piping cat to sort.
grep
grep, egrep, fgrep - print lines matching a patternLet's pretend that I only care about finding an order for PofEAA. Using grep I can limit my results to PofEAA transactions.
jfields$ cat order.* | sort | grep Patterns 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99Assume that an issue occurred with the refund on order 113, and you want to see all data related to that order - grep is your friend again.
jfields$ cat order.* | sort | grep ":\d\d 113, " 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:24:20 113, Refund sent to processingYou'll notice that I put a bit more than "113" in my regex for grep. This is because 113 can also come up in a product title or a price. With a few extra characters, I can limit the results to strictly the transactions I'm looking for.
Now that we've sent the order details on to refunds, we also want to send the daily totals of sales and refunds on to the accounting team. They've asked for each line item for PofEAA, but they only care about the quantity and price. What we need to do is cut out everything we don't care about.
cut
cut - remove sections from each line of filesUsing grep again, we can see that we grab the appropriate lines. Once we grab what we need, we can cut the line up into pieces, and rid ourselves of the unnecessary data.
jfields$ cat order.* | sort | grep Patterns 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99 jfields$ cat order.* | sort | grep Patterns | cut -d"," -f2,5 1, 39.99 -1, 39.99At this point we've reduced our data down to what accounting is looking for, so it's time to paste it into a spreadsheet and be done with that task.
Using cut is helpful in tracking down problems, but if you're generating an output file you'll often want something more complicated. Let's assume that accounting also needs to know the order ids for building some type of reference documentation. We can get the information using cut, but the accounting team wants the order id to be at the end of the line, and surrounded in single quotes. (for the record, you might be able to do this with cut, I've never tried)
sed
sed - A stream editor. A stream editor is used to perform basic text transformations on an input stream.The following example shows how we can use sed to transform our lines in the requested way, and then cut is used to remove unnecessary data.
jfields$ cat order.* | sort | grep Patterns \ >| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/ 1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '111' -1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '113' lmp-jfields01:~ jfields$ cat order.* | sort | grep Patterns \ >| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/ | cut -d"," -f1,4,5 1, 39.99, '111' -1, 39.99, '113'There's a bit going on in that example regex, but nothing too complicated. The regex does the following things
- remove the timestamp
- capture the order number
- remove the comma and space after the order number
- capture the remainder of the line
Once we've captured the data we need, we can use \1 & \2 to reorder and output the data in our desired format. We also include the requested double quotes, and add our own comma to keep our format consistent. Finally, we use cut to remove the superfluous data.
Now you're in trouble. You've demonstrated that you can slice up a log file in fairly short order, and the CIO needs a quick report of the total number of book transactions broken down by book.
uniq
uniq - removes duplicate lines from a uniqed file(we'll assume that other types of transactions can take place and 'filter' our in file for 'Kindle' and 'Hardcover')
The following example shows how to grep for only book related transactions, cut unnecessary information, and get a counted & unique list of each line.
jfields$ cat order.out.log | grep "\(Kindle\|Hardcover\)" | cut -d"," -f3 | sort | uniq -c 1 Joy of Clojure 2 Patterns of Enterprise ArchitectureHad the requirements been a bit simpler, say "get me a list of all books with transactions", uniq also would have been the answer.
jfields$ cat order.out.log | grep "\(Kindle\|Hardcover\)" | cut -d"," -f3 | sort | uniq Joy of Clojure Patterns of Enterprise ArchitectureAll of these tricks work well, if you know where to find the file you need; however, sometimes you'll find yourself in a deeply nested directory structure without any hints as to where you need to go. If you're lucky enough to know the name of the file you need (or you have a decent guess) you shouldn't have any trouble finding what you need.
find
find - search for files in a directory hierarchyIn our above examples we've been working with order.in.log and order.out.log. On my box those files exist in my home directory. The following example shows how to find those files from a higher level, without even knowing the full filename.
jfields$ find /Users -name "order*" Users/jfields/order.in.log Users/jfields/order.out.logFind has plenty of other options, but this does the trick for me about 99% of the time.
Along the same lines, once you find a file you need, you're not always going to know what's in it and how you want to slice it up. Piping the output to standard out works fine when the output is short; however, when there's a bit more data than what fits on a screen, you'll probably want to pipe the output to less.
less
less - allows forward & backward movement within a fileAs an example, let's go all the way back to our simple cat | sort example. If you execute the following command you'll end up in less, with your in & out logs merged and sorted. Within less you can forward search with "/" and backward search with "?". Both searches take a regex.
jfields$ cat order* | sort | lessWhile in less you can try /113.*, which will highlight all transactions for order 113. You can also try ?.*112, which will highlight all timestamps associated with order 112. Finally, you can use 'q' to quit less.
The linux command line is rich, and someone intimidating. However, with the previous 8 commands, you should be able to get quite a few log slicing tasks completed - without having to drop to your favorite scripting language.
* okay, possibly Unix, that's not the point
Wednesday, June 27, 2012
Sharing Blog Example Code
I've been blogging since 2005, using various tools for publishing readable code. Originally you'd just put code out there, no colors, just a pre tag and some indention. Then 'export to html' became pretty standard in various editors, and everyone's life got better. These days, people want code examples available to play with - and I use GitHub to make that possible.
I've been toying with different formats for sharing code, and my last blog entry demonstrates what I've settled on.
I've been toying with different formats for sharing code, and my last blog entry demonstrates what I've settled on.
- Each blog entry with a non-trivial amount of code will live in a repository owned by blog-jayfields-com
- Commits will contain working code that can be executed (if possible)
- I'll use gist-it to embed code that can be found in the GitHub repo
- I'll create a gh-pages index.html with the content of the blog entry, for people to review and provide feedback.
Tuesday, June 26, 2012
Reading Clojure Stacktraces
Clojure stacktraces are not incredibly user friendly. Once I got used to the status quo, I forgot how much noise lives within a stacktrace; however, every so often a Clojure beginner will remind the community that stacktraces are a bit convoluted. You can blame the JWM, lack of prioritization from the Clojure community, or someone else if you wish, but the reality is - I don't expect stacktraces to change anytime soon. This blog entry is about separating the signal from the noise within a stacktrace.
note: all code for this blog entry can be found at: http://github.com/blog-jayfields-com/Reading-Clojure-Stacktraces
Let's start with a very simple example.
Running (I'm using 'lein run') the above code you should get a stacktrace that looks like the output below.
In this example, user$eval... likely has something to do with lein, and I can safely assume that the problem is likely not in there. Moving up from there I can see a line from my code:
Moving up another line, I can see that the issue is likely inside the 'foo' function of the reading-clojure-stacktraces namespace. A quick review of the original code shows that line 3 of core.clj contains the call to throw, and everything makes perfect sense.
If all Clojure stacktraces were this simple, I probably wouldn't bother with this blog entry; however, things can become a bit more complicated as you introduce anonymous functions.
The following snippet of code removes the 'foo' function and throws an exception from within an anonymous function.
Another trip to 'lein run' produces the following output.
I expect you'd be able to find the issue with our contrived example without any further help; however, production code (often making use of high order functions) can lead to significantly more complex stacktraces. You could forsake anonymous functions, but there's a nice middle ground that is also helpful for debugging - temporarily name your anonymous functions.
Clojure's reader transforms the Anonymous function literal in the following way.
Another quick 'lein run' verifies that the stacktrace is the same (and I see no reason to repeat it here). However, now that we've switched to fn, we can provide a (rarely used, optional) name.
At this point, 'lein run' should produce the following output.
The following snippet of code throws a NullPointerException due to a mistake I clearly made, but the last line of 'my code' is in the lower half of a long stacktrace.
The above example code produces the below stacktrace.
If you look at line 7 of (reading-clojure-stacktraces) core.clj, you'll notice that I'm merely printing the results of calling foo - yet the issue seems to be with the map function that is invoked within foo. This is because map is lazy, and the evaluation is deferred until we attempt to print the results of mapping inc. While it's not exactly obvious, the stacktrace does contain all the hints we need to find the issue. Line 3 lets us know that inc is getting a nil. Line 4 lets us know that it's happening inside a map. Line 5 lets us know that we're dealing with laziness. And, the line containing our namespace lets us know where to begin looking.
The following example is very similar; however, it uses a partial to achieve the same result.
The above example code produces the below stacktrace.
Skimming for hints may look painful at first. However, you quickly learn to filter out the common Clojure related noise. For example, anything that starts with 'clojure' and looks like a standard Java class name is highly unlikely to be where a problem exists. For example, clojure.lang.Numbers.ops isn't likely to have a bug. Likewise, you'll often see the same classes and methods repeated across all possible errors - clojure.lang.AFn, clojure.lang.RestFn, clojure.core$apply, clojure.lang.LazySeq, clojure.lang.RT, clojure.lang.MultiFn, etc, etc. These functions are often used building blocks for almost everything Clojure does. Those lines provide a bit of signal, but (for the most part) can safely be ignored.
Again, it can be a bit annoying to deal with Clojure stacktraces when getting started; however, if you take the time to understand which lines are signal and which lines are noise, then they become helpful debugging tools.
related: If you want a testing library that helps you filter some of the stacktrace noise, you might want to check out expectations.
note: all code for this blog entry can be found at: http://github.com/blog-jayfields-com/Reading-Clojure-Stacktraces
Let's start with a very simple example.
Running (I'm using 'lein run') the above code you should get a stacktrace that looks like the output below.
lmp-jfields03:reading-clojure-stacktraces jfields$ lein run Exception in thread "main" java.lang.RuntimeException: thrown at reading_clojure_stacktraces.core$foo.invoke(core.clj:3) at reading_clojure_stacktraces.core$_main.invoke(core.clj:6) at clojure.lang.Var.invoke(Var.java:397) at user$eval37.invoke(NO_SOURCE_FILE:1) at clojure.lang.Compiler.eval(Compiler.java:6465) at clojure.lang.Compiler.eval(Compiler.java:6455) [blah blah blah]I snipped a fair bit of stacktrace and replaced it with [blah blah blah]. I did that because that's what I mentally do as well, I look for the last line that includes a file that I've created and I ignore everything after a few lines below my line. That is my first recommendation - If you see a stacktrace, it's likely that the problem is in your code, not Clojure. Look for the last line of your code (N) and ignore every line below N + 3.
In this example, user$eval... likely has something to do with lein, and I can safely assume that the problem is likely not in there. Moving up from there I can see a line from my code:
reading_clojure_stacktraces.core$_main.invoke(core.clj:6)When I read the above line I see the problem is in namespace 'reading-clojure-stacktraces/core', in the function '-main', in the file core.clj, on line 6. I'm no Clojure internals expert, but I believe Clojure actually creates a class named reading_clojure_stacktraces.core$_main with an 'invoke' method; however, I truthfully don't know (and you wont need to either). Whether a class is created or not, it makes sense that the line will need to be formatted to fit a valid Java class name - which explains why our dashes have been converted to underscores.
Moving up another line, I can see that the issue is likely inside the 'foo' function of the reading-clojure-stacktraces namespace. A quick review of the original code shows that line 3 of core.clj contains the call to throw, and everything makes perfect sense.
If all Clojure stacktraces were this simple, I probably wouldn't bother with this blog entry; however, things can become a bit more complicated as you introduce anonymous functions.
The following snippet of code removes the 'foo' function and throws an exception from within an anonymous function.
Another trip to 'lein run' produces the following output.
Exception in thread "main" java.lang.RuntimeException: thrown at reading_clojure_stacktraces.core$_main$fn__9.invoke(core.clj:4) at reading_clojure_stacktraces.core$_main.invoke(core.clj:4) at clojure.lang.Var.invoke(Var.java:397) at user$eval38.invoke(NO_SOURCE_FILE:1) at clojure.lang.Compiler.eval(Compiler.java:6465)The above stacktrace does give you the correct file and line number of where the issue originates; however, you'll notice that the function that threw the exception has become a bit less easy to identify. My use of an anonymous function led to Clojure naming the function fn__9, and there's nothing wrong with that. In fact, this example is especially readable as the stacktrace shows that fn__9 was created inside the -main function.
I expect you'd be able to find the issue with our contrived example without any further help; however, production code (often making use of high order functions) can lead to significantly more complex stacktraces. You could forsake anonymous functions, but there's a nice middle ground that is also helpful for debugging - temporarily name your anonymous functions.
Clojure's reader transforms the Anonymous function literal in the following way.
#(...) => (fn [args] (...))Therefore, the following code will be the same as the example above, from Clojure's perspective.
Another quick 'lein run' verifies that the stacktrace is the same (and I see no reason to repeat it here). However, now that we've switched to fn, we can provide a (rarely used, optional) name.
At this point, 'lein run' should produce the following output.
Exception in thread "main" java.lang.RuntimeException: thrown at reading_clojure_stacktraces.core$_main$i_throw__9.invoke(core.clj:4) at reading_clojure_stacktraces.core$_main.invoke(core.clj:4) at clojure.lang.Var.invoke(Var.java:397) at user$eval38.invoke(NO_SOURCE_FILE:1) at clojure.lang.Compiler.eval(Compiler.java:6465)Now our line contains a bit more information. The two $ signs still indicate that the function with an issue is a function created inside -main; however, our stacktrace also includes the name (in bold) we specified for our function. You can use any valid symbol characters, so feel free to put anything you want in the name while you're debugging.
note: Symbols begin with a non-numeric character and can contain alphanumeric characters and *, +, !, -, _, and ? -- clojure.org.So far, all of the examples have been somewhat noisy, but mildly easy to mentally filter. Unfortunately, idiomatic Clojure code can also lead to stacktraces that bounce back and forth between your code and the standard library, leaving you to sift through significantly longer stacktraces.
The following snippet of code throws a NullPointerException due to a mistake I clearly made, but the last line of 'my code' is in the lower half of a long stacktrace.
The above example code produces the below stacktrace.
Exception in thread "main" java.lang.NullPointerException at clojure.lang.Numbers.ops(Numbers.java:942) at clojure.lang.Numbers.inc(Numbers.java:110) at clojure.core$inc.invoke(core.clj:862) at clojure.core$map$fn__3811.invoke(core.clj:2430) at clojure.lang.LazySeq.sval(LazySeq.java:42) at clojure.lang.LazySeq.seq(LazySeq.java:60) at clojure.lang.RT.seq(RT.java:466) at clojure.core$seq.invoke(core.clj:133) at clojure.core$print_sequential.invoke(core_print.clj:46) at clojure.core$fn__4990.invoke(core_print.clj:140) at clojure.lang.MultiFn.invoke(MultiFn.java:167) at clojure.core$pr_on.invoke(core.clj:3264) at clojure.core$pr.invoke(core.clj:3276) at clojure.lang.AFn.applyToHelper(AFn.java:161) at clojure.lang.RestFn.applyTo(RestFn.java:132) at clojure.core$apply.invoke(core.clj:600) at clojure.core$prn.doInvoke(core.clj:3309) at clojure.lang.RestFn.applyTo(RestFn.java:137) at clojure.core$apply.invoke(core.clj:600) at clojure.core$println.doInvoke(core.clj:3329) at clojure.lang.RestFn.invoke(RestFn.java:408) at reading_clojure_stacktraces.core$_main.invoke(core.clj:7) at clojure.lang.Var.invoke(Var.java:397) at user$eval37.invoke(NO_SOURCE_FILE:1) at clojure.lang.Compiler.eval(Compiler.java:6465) at clojure.lang.Compiler.eval(Compiler.java:6455)In situations like these, I generally look at the top few lines to get a bit of context, and then I scroll down to find the last line of 'my code'. Looking at the top 4 lines from the stacktrace I can see that the issue is with the inc function, which was passed to the high order function named map. If I look father down the stacktrace, I can see that line 7 in reading-clojure-stacktraces.core is where the issue began in 'my code'.
If you look at line 7 of (reading-clojure-stacktraces) core.clj, you'll notice that I'm merely printing the results of calling foo - yet the issue seems to be with the map function that is invoked within foo. This is because map is lazy, and the evaluation is deferred until we attempt to print the results of mapping inc. While it's not exactly obvious, the stacktrace does contain all the hints we need to find the issue. Line 3 lets us know that inc is getting a nil. Line 4 lets us know that it's happening inside a map. Line 5 lets us know that we're dealing with laziness. And, the line containing our namespace lets us know where to begin looking.
The following example is very similar; however, it uses a partial to achieve the same result.
The above example code produces the below stacktrace.
Exception in thread "main" java.lang.NullPointerException at clojure.lang.Numbers.ops(Numbers.java:942) at clojure.lang.Numbers.add(Numbers.java:126) at clojure.core$_PLUS_.invoke(core.clj:927) at clojure.lang.AFn.applyToHelper(AFn.java:163) at clojure.lang.RestFn.applyTo(RestFn.java:132) at clojure.core$apply.invoke(core.clj:602) at clojure.core$partial$fn__3794.doInvoke(core.clj:2341) at clojure.lang.RestFn.invoke(RestFn.java:408) at clojure.core$map$fn__3811.invoke(core.clj:2430) at clojure.lang.LazySeq.sval(LazySeq.java:42) at clojure.lang.LazySeq.seq(LazySeq.java:60) at clojure.lang.RT.seq(RT.java:466) at clojure.core$seq.invoke(core.clj:133) at clojure.core$print_sequential.invoke(core_print.clj:46) at clojure.core$fn__4990.invoke(core_print.clj:140) at clojure.lang.MultiFn.invoke(MultiFn.java:167) at clojure.core$pr_on.invoke(core.clj:3264) at clojure.core$pr.invoke(core.clj:3276) at clojure.lang.AFn.applyToHelper(AFn.java:161) at clojure.lang.RestFn.applyTo(RestFn.java:132) at clojure.core$apply.invoke(core.clj:600) at clojure.core$prn.doInvoke(core.clj:3309) at clojure.lang.RestFn.applyTo(RestFn.java:137) at clojure.core$apply.invoke(core.clj:600) at clojure.core$println.doInvoke(core.clj:3329) at clojure.lang.RestFn.invoke(RestFn.java:408) at reading_clojure_stacktraces.core$_main.invoke(core.clj:7) at clojure.lang.Var.invoke(Var.java:397) at user$eval37.invoke(NO_SOURCE_FILE:1) at clojure.lang.Compiler.eval(Compiler.java:6465)Again, you'll want to skim the stacktrace for hints. In the above stacktrace we can see that line 3 is telling us that + is the issue. Line 7 lets us know that partial was used. And, the remaining hints are the same as the previous example.
Skimming for hints may look painful at first. However, you quickly learn to filter out the common Clojure related noise. For example, anything that starts with 'clojure' and looks like a standard Java class name is highly unlikely to be where a problem exists. For example, clojure.lang.Numbers.ops isn't likely to have a bug. Likewise, you'll often see the same classes and methods repeated across all possible errors - clojure.lang.AFn, clojure.lang.RestFn, clojure.core$apply, clojure.lang.LazySeq, clojure.lang.RT, clojure.lang.MultiFn, etc, etc. These functions are often used building blocks for almost everything Clojure does. Those lines provide a bit of signal, but (for the most part) can safely be ignored.
Again, it can be a bit annoying to deal with Clojure stacktraces when getting started; however, if you take the time to understand which lines are signal and which lines are noise, then they become helpful debugging tools.
related: If you want a testing library that helps you filter some of the stacktrace noise, you might want to check out expectations.
Thursday, June 21, 2012
Clojure: Production Web REPL
A REPL is a powerful tool. I use the REPL extensively in development, and I recently added a web REPL to each of our production applications.
Context
A production REPL is not for the faint of heart. I wouldn't add a REPL to production in 95% of the projects I've been a part of; however, I'm currently working with two other developers that I completely trust with the power of a production REPL. As a simple rule, I wouldn't give access to a production REPL to anyone that doesn't also have root access to the server - if you can't be trusted with one, it's likely that you can't be trusted with the other. However, if you can be trusted, I'd rather you have all of your tools available to you.
Don't get the wrong impression, I'm not regularly redefining functions in production. I rarely use a prod REPL, but when I do, I almost always use it to read reference data. On the very rare occasion, I'll wrap an existing function with a new version that logs the value of the incoming arguments. In short, I use the prod REPL (again, sparingly) to gather more data, not to fix outstanding bugs. I'm not saying I would never use it to fix a bug, but that would be an extremely exceptional case.
Code
It's actually very easy to plug a web REPL into a Clojure application that already has a web interface. The Clojure applications I work on tend to have web sockets, and the following solution uses web sockets; however, there's no reason that you couldn't use simple web requests and responses. Lastly, I didn't actually write this code. Someone at DRW wrote it (I have no idea who) and it's been copy-pasted several times since then. Without further adieu, the code:
Context
A production REPL is not for the faint of heart. I wouldn't add a REPL to production in 95% of the projects I've been a part of; however, I'm currently working with two other developers that I completely trust with the power of a production REPL. As a simple rule, I wouldn't give access to a production REPL to anyone that doesn't also have root access to the server - if you can't be trusted with one, it's likely that you can't be trusted with the other. However, if you can be trusted, I'd rather you have all of your tools available to you.
sidebar: the most interesting story I've heard about a REPL in prod was the following - Debugging a program running on a $100M piece of hardware that is 100 million miles away is an interesting experience. Having a read-eval-print loop running on the spacecraft proved invaluable in finding and fixing the problem. -- Lisping at JPLMotivation
Don't get the wrong impression, I'm not regularly redefining functions in production. I rarely use a prod REPL, but when I do, I almost always use it to read reference data. On the very rare occasion, I'll wrap an existing function with a new version that logs the value of the incoming arguments. In short, I use the prod REPL (again, sparingly) to gather more data, not to fix outstanding bugs. I'm not saying I would never use it to fix a bug, but that would be an extremely exceptional case.
Code
It's actually very easy to plug a web REPL into a Clojure application that already has a web interface. The Clojure applications I work on tend to have web sockets, and the following solution uses web sockets; however, there's no reason that you couldn't use simple web requests and responses. Lastly, I didn't actually write this code. Someone at DRW wrote it (I have no idea who) and it's been copy-pasted several times since then. Without further adieu, the code:
Wednesday, June 20, 2012
Signs That Your Project Team Might Be Too Large
Amanda Laucher recently queried the twitterverse on the topic of team size.

In my opinion, my last project team was "too large". This blog entry will focus on the things that happened that drove me to that conclusion.
note: I was the only person on the team who believed it was too large. The rest of the team thought we 'might' be too large, and the cost of making a change was greater than the pain of remaining 'potentially' too large. Since I was the minority, it's safe to assume that my opinion is controversial at a minimum.
In many ways my last project was a very, very well funded start-up. We started small, with 3 developers; however, as the scope of our problem grew so went the size of our team. When the team had reached 7 (5 developers in one office and 2 in another), I began to advocate for a team split. By the time we reached 10 total, I was positive that a split was appropriate. As I stated, we were in start-up mode. I wanted to deliver as fast as possible and I felt that several factors were impacting our ability to produce.
Camps. Technology choices originally drove my desire to split the team. The project had speed requirements that forced the use of Java for some portions of our solution; however, other portions of the codebase could have been written using Java, Clojure, or even Ruby. I held the opinion that anything that could be written in Clojure should be written in Clojure. I felt faster writing code in Clojure (vs Java) and I wanted to deliver as fast as I possibly could. Two of my colleagues agreed with my opinion, 2 abstained, and 2 strongly disagreed with me. The two that disagreed with me thought it was easier to write everything in one language, using one toolset. I completely see their point of view, and acknowledge all of their opinions. They are not wrong, we just have incompatible opinions on software.
I need to be clear here, these were good developers. It would have been easy if they were inferior developers - we would have improved their skills or found them a new home. However, that wasn't the case. These were guys that consistently delivered as much, if not more value than I did - they just wanted to get things done is a way that clashed with my approach. The team was more or less split into 2 camps - pro Clojure and pro Java.
Countless hours were spent discussing how to deal with this difference of opinions. Retrospectives were often composed of 2 types of problems: Problems that we all agreed on and solved, and problems that we would never agree on and never solved. The 2nd types of problems appeared at every retrospective and always led to the same interaction.
Depth Shortage. Agile Enthusiasts loved to point out the benefits of Collective Code Ownership - and they are undeniable when contrasted with Strong Code Ownership. However, I believe that Collective Code Ownership actually hindered the delivery pace of the previously referenced development team. Collective Code Ownership combined with our team size resulted in many team members having breadth of knowledge, but lacking depth of knowledge of the system.
After a year of practicing Collective Code Ownership I found that most areas of the codebase would have a primary person who deeply understood it's purpose, and almost everyone else knew very, very little about it. Those with shallow knowledge could successfully edit a method, but a change of greater size would require pairing with the primary person. The problem was large, and we were spread too thin.
The application was already split into logical components, and my solution was to move to a Weak Code Ownership model - with the requirement that each component would have at least 3 "owners" that deeply understood each component. You would still be required to know what each component did, but you wouldn't ever be required to even look at the code for that component. I believe this solution would have solved our depth issue, but so would breaking up our large team.
If your team is so large that working in every area of the codebase results in shallow knowledge of over 40% of your codebase, that might be a sign that you could benefit from splitting the team into smaller groups with more specific responsibilities.
And, just in case you are wondering, pairing isn't the solution to having a team that is too big.
I'd like to thank the following people for reviewing and providing feedback on this entry: J. B. Rainsberger, Peter Royal, Nick Drew, Mike Rettig, John Hume, Clinton Begin, Pat Kua, Nat Pryce, Patrick Farley, & Dan North.

In my opinion, my last project team was "too large". This blog entry will focus on the things that happened that drove me to that conclusion.
note: I was the only person on the team who believed it was too large. The rest of the team thought we 'might' be too large, and the cost of making a change was greater than the pain of remaining 'potentially' too large. Since I was the minority, it's safe to assume that my opinion is controversial at a minimum.
In many ways my last project was a very, very well funded start-up. We started small, with 3 developers; however, as the scope of our problem grew so went the size of our team. When the team had reached 7 (5 developers in one office and 2 in another), I began to advocate for a team split. By the time we reached 10 total, I was positive that a split was appropriate. As I stated, we were in start-up mode. I wanted to deliver as fast as possible and I felt that several factors were impacting our ability to produce.
Camps. Technology choices originally drove my desire to split the team. The project had speed requirements that forced the use of Java for some portions of our solution; however, other portions of the codebase could have been written using Java, Clojure, or even Ruby. I held the opinion that anything that could be written in Clojure should be written in Clojure. I felt faster writing code in Clojure (vs Java) and I wanted to deliver as fast as I possibly could. Two of my colleagues agreed with my opinion, 2 abstained, and 2 strongly disagreed with me. The two that disagreed with me thought it was easier to write everything in one language, using one toolset. I completely see their point of view, and acknowledge all of their opinions. They are not wrong, we just have incompatible opinions on software.
I need to be clear here, these were good developers. It would have been easy if they were inferior developers - we would have improved their skills or found them a new home. However, that wasn't the case. These were guys that consistently delivered as much, if not more value than I did - they just wanted to get things done is a way that clashed with my approach. The team was more or less split into 2 camps - pro Clojure and pro Java.
Countless hours were spent discussing how to deal with this difference of opinions. Retrospectives were often composed of 2 types of problems: Problems that we all agreed on and solved, and problems that we would never agree on and never solved. The 2nd types of problems appeared at every retrospective and always led to the same interaction.
- someone (usually me) bitched about the lack consistency on the team
- people from my camp agreed that it was an issue, and spoke in generic terms (not wanting to target or alienate anyone).
- people from the opposing camp made their (completely valid) points.
- the room became awkwardly silent; everyone knew we were at an impass
- someone made a joke to ease tensions
- we moved on, no resolution
reviewer feedbackIf your team has camps with incompatible (yet, perfectly valid) opinions then it's a sign that it's possibly too big, or it has members that would be more effectively used if swapped with someone else in the organization that holds compatible opinions. Or, more precisely, if you have camps (where camp is defined as N or more people) with conflicting opinions, and you have a solution that can be split vertically or horizontally, then your team size may be "too big" - where too big is defined as "a split would likely increase the productivity of the members of both camps". It could be possible to replace X split-away members with Y new members where (Y > X) and as long as you do not have camps, the team would not be considered too big - which is why you cannot simply state that Z people on a team is 'too big'. note: N is defined as the number of people required to reasonably address bus risk. On a highly functional team with almost no turnover, N can equal 2. More often, N will be 3 or more.On Jun 18, 2012, Patrick Farley wrote:I do believe it is more likely that camps occur as the team sizes grow. I believe disagreements are healthy; however, camps are counterproductive - due to too much time spent in arbitration. I do agree that you can have camps on a team size two, and it's possible to have no camps on a team of size 10 - which is why I don't think size X will guarantee camps, but that if you have camps then X might be too many.
I think your points about non-compatible opinions on a team, in the saddest case, can occur on a team of two. Do you suppose two distinct camps (as opposed to a bickering mob) become more likely as team size grows?
Depth Shortage. Agile Enthusiasts loved to point out the benefits of Collective Code Ownership - and they are undeniable when contrasted with Strong Code Ownership. However, I believe that Collective Code Ownership actually hindered the delivery pace of the previously referenced development team. Collective Code Ownership combined with our team size resulted in many team members having breadth of knowledge, but lacking depth of knowledge of the system.
reviewer feedbackThe problem we were solving had 3rd party, distributed system, compliance, extreme performance, and algorithmic concerns that all needed attention. On the surface it didn't seem like a tough problem to solve, and yet, not a single member of the best team I've ever worked on could explain the entire problem. In short, it wasn't just complicated, it was deceptively complicated - which made matters worse. The problem was large, and we attempted to tackle it (clearly, not intentionally) by building a team that was too large.On Jun 18, 2012, J. B. Rainsberger wrote:Definitely the latter. Our problem had grown to a size that caused CCO to go from a positive impact to a negative one. This was not due to a flaw in CCO, this was due to applying CCO to a situation where it was no longer the most effective choice.
Do you believe that CCO hindered the pace of delivery, or that the code base grew to a size and level of complication that made it hard to own collectively?
After a year of practicing Collective Code Ownership I found that most areas of the codebase would have a primary person who deeply understood it's purpose, and almost everyone else knew very, very little about it. Those with shallow knowledge could successfully edit a method, but a change of greater size would require pairing with the primary person. The problem was large, and we were spread too thin.
The application was already split into logical components, and my solution was to move to a Weak Code Ownership model - with the requirement that each component would have at least 3 "owners" that deeply understood each component. You would still be required to know what each component did, but you wouldn't ever be required to even look at the code for that component. I believe this solution would have solved our depth issue, but so would breaking up our large team.
If your team is so large that working in every area of the codebase results in shallow knowledge of over 40% of your codebase, that might be a sign that you could benefit from splitting the team into smaller groups with more specific responsibilities.
And, just in case you are wondering, pairing isn't the solution to having a team that is too big.
I'd like to thank the following people for reviewing and providing feedback on this entry: J. B. Rainsberger, Peter Royal, Nick Drew, Mike Rettig, John Hume, Clinton Begin, Pat Kua, Nat Pryce, Patrick Farley, & Dan North.
Tuesday, June 19, 2012
organizing a speakerconf
About 5 years ago I expressed an idea to Josh Graham.
The Beginning
Once Josh created the website I knew it was time to see if we could actually make the event happen. I started by emailing my network to see who liked the idea and would attend. I always knew that 15 was the minimum number of presenters that I would want for a speakerconf, so I sent the emails and waited to see if we had enough interest or not - luckily we did. I also knew I wanted to have a group dinner every night, and the only way to convince 15 people to attend the same restaurant was to pay the bill - so I set out to find sponsors. The management at DRW is incredibly supportive and they quickly offered to sponsor. I also had a great relationship with Forward and they immediately offered to sponsor as well. With both of those sponsors committed, we had the minimum amount of money required to pay for the conference room and cover the cost of the group dinners. At that point there was no looking back, and we began building the hype via Twitter.
Quality, not Quantity
I believed that getting a commitment from a few high-profile speakers would cause plenty of other speakers to jump on board, but the speakerconf idea didn't really generate much buzz the first year (from my point of view). Once the idea became a reality, things changed drastically. The first event was a huge success. We had over 30 people sign up for speakerconf 2010 (in those days, if anyone you knew was going you could go as well). The second event was also a success, but we all agreed that 30+ was too many people. Following 2010, speakerconf became an invite only event and was limited to 25 people.
We were happy with 25 people at each speakerconf, but we ended up learning that less is an even better situation. speakerconf Aruba 2012 had 12 people cancel, which left us in a terrible place. Replacing a speakerconf presenter is extremely hard. The net result was that only 18 people attended, and it worked out perfectly. The collaboration, quality, and enjoyment all seemed to go up significantly. I believe it became a case of addition by subtraction, due to the interactions becoming much richer. After the success of Aruba 2012 Josh and I decided that future speakerconfs will have between 18-20 presenters.
Another Point of View
At speakerconf, your participation in discussion is just as important as your presentation. At the first few speakerconfs I had unreal expectations about people spending every waking minute participating. It was the center of attention for Josh and I, but for the presenters it was just a great event that they needed to responsibly balance with their other commitments. After the first 2 speakerconfs I learned that we needed to set aside time for everyone to take care of work and personal business. At this point, Josh and I allocate 2 hours before dinner each night where presenters can take care of non-speakerconf related issues.
You do not talk about speakerconf
As programmers, we like to optimize. Sadly, I've wasted countless hours and other people's time at speakerconf by discussing how to tweak speakerconf. My intentions were good, I wanted to improve the event. Unfortunately, there's two issues with this: We could be talking about technology instead, and it brings attention to any issues I'm noticing. I believe the old advice that the party takes on the mood of the host - and I don't want to bring speakerconf presenters into my perfectionist world that constantly focuses on otherwise unseen flaws. Plus, if I'm hanging out with some of the best from our industry, it's much more beneficial to hear about what they're working on these days.
I'm not going to lie, it's not easy to stop myself for asking for feedback while the event is running, but I do believe it's the right choice. I'm more than happy to discuss tweaks if someone else brings it up, and I definitely solicit feedback once the event is over; however, speakerconf time is for discussing technology, and the conference benefits when I remember that simple suggestion.
The Best, Last
The last 2 lessons are unquestionably the most important: be flexible and get a co-founder. Brian Goetz mentioned to me many times - get smart people together and let them figure out how to have a good time. Whenever people suggest we tweak something, Josh and I do our best to accomodate and see where it takes us. Above all else, we remove distractions and get out of the way, so presentations or ideas can reach their full potential. Occasionally that means letting a presentation run long, switching the presentation order, taking a quick break, or moving to open discussion ahead of schedule. The schedule always suffers, but the experience always benefits. At this point, Josh and I have learned to roll with whatever comes our way, as long as it enhances speakerconf.
speakerconf requires Josh. I hear it's true that start-ups need a co-founder, and I couldn't have done speakerconf without Josh. I tell him I'm quitting at least once a year. Josh seemed like he might quit last year. However, we carry each other when we need to, and I'm very proud of what we put out each year.
Let's take the parts of traditional conferences that the presenters like the most, and make that an entire conference. Specifically, we should have plenty of discussion time with drinks available & we should have group dinners every night.I'd expressed this idea to a few different people, and never done anything with it. Luckily, by the time I'd woken up the following morning, Josh had already set up the speakerconf website. Organizing speakerconf has been an interesting and enlightening journey. The past few blog posts have been about what speakerconf is, what presenters are responsible for, & logistics - this post is about how we got started and the organization and participation lessons I learned.
The Beginning
Once Josh created the website I knew it was time to see if we could actually make the event happen. I started by emailing my network to see who liked the idea and would attend. I always knew that 15 was the minimum number of presenters that I would want for a speakerconf, so I sent the emails and waited to see if we had enough interest or not - luckily we did. I also knew I wanted to have a group dinner every night, and the only way to convince 15 people to attend the same restaurant was to pay the bill - so I set out to find sponsors. The management at DRW is incredibly supportive and they quickly offered to sponsor. I also had a great relationship with Forward and they immediately offered to sponsor as well. With both of those sponsors committed, we had the minimum amount of money required to pay for the conference room and cover the cost of the group dinners. At that point there was no looking back, and we began building the hype via Twitter.
Quality, not Quantity
I believed that getting a commitment from a few high-profile speakers would cause plenty of other speakers to jump on board, but the speakerconf idea didn't really generate much buzz the first year (from my point of view). Once the idea became a reality, things changed drastically. The first event was a huge success. We had over 30 people sign up for speakerconf 2010 (in those days, if anyone you knew was going you could go as well). The second event was also a success, but we all agreed that 30+ was too many people. Following 2010, speakerconf became an invite only event and was limited to 25 people.
We were happy with 25 people at each speakerconf, but we ended up learning that less is an even better situation. speakerconf Aruba 2012 had 12 people cancel, which left us in a terrible place. Replacing a speakerconf presenter is extremely hard. The net result was that only 18 people attended, and it worked out perfectly. The collaboration, quality, and enjoyment all seemed to go up significantly. I believe it became a case of addition by subtraction, due to the interactions becoming much richer. After the success of Aruba 2012 Josh and I decided that future speakerconfs will have between 18-20 presenters.
Another Point of View
At speakerconf, your participation in discussion is just as important as your presentation. At the first few speakerconfs I had unreal expectations about people spending every waking minute participating. It was the center of attention for Josh and I, but for the presenters it was just a great event that they needed to responsibly balance with their other commitments. After the first 2 speakerconfs I learned that we needed to set aside time for everyone to take care of work and personal business. At this point, Josh and I allocate 2 hours before dinner each night where presenters can take care of non-speakerconf related issues.
You do not talk about speakerconf
As programmers, we like to optimize. Sadly, I've wasted countless hours and other people's time at speakerconf by discussing how to tweak speakerconf. My intentions were good, I wanted to improve the event. Unfortunately, there's two issues with this: We could be talking about technology instead, and it brings attention to any issues I'm noticing. I believe the old advice that the party takes on the mood of the host - and I don't want to bring speakerconf presenters into my perfectionist world that constantly focuses on otherwise unseen flaws. Plus, if I'm hanging out with some of the best from our industry, it's much more beneficial to hear about what they're working on these days.
I'm not going to lie, it's not easy to stop myself for asking for feedback while the event is running, but I do believe it's the right choice. I'm more than happy to discuss tweaks if someone else brings it up, and I definitely solicit feedback once the event is over; however, speakerconf time is for discussing technology, and the conference benefits when I remember that simple suggestion.
The Best, Last
The last 2 lessons are unquestionably the most important: be flexible and get a co-founder. Brian Goetz mentioned to me many times - get smart people together and let them figure out how to have a good time. Whenever people suggest we tweak something, Josh and I do our best to accomodate and see where it takes us. Above all else, we remove distractions and get out of the way, so presentations or ideas can reach their full potential. Occasionally that means letting a presentation run long, switching the presentation order, taking a quick break, or moving to open discussion ahead of schedule. The schedule always suffers, but the experience always benefits. At this point, Josh and I have learned to roll with whatever comes our way, as long as it enhances speakerconf.
speakerconf requires Josh. I hear it's true that start-ups need a co-founder, and I couldn't have done speakerconf without Josh. I tell him I'm quitting at least once a year. Josh seemed like he might quit last year. However, we carry each other when we need to, and I'm very proud of what we put out each year.
Thursday, June 14, 2012
trust at speakerconf
Trust plays a very important role at speakerconf. speakerconf is known as a place where you can be honest without fear of repercussions. Every year we have several presentations that are confidential, and those are often some of the most interesting presentations. Josh and I have made several decisions that encourage a high level of trust, and this blog entry describes those choices.
... it's who you know
Josh and I don't tend to keep people we can't trust within our networks. Therefore, when we began inviting people to speakerconf we already knew we were assembling a group of people that could be honest with each other. I believe the speakers had mutual trust with Josh and I, and that trust was easily extended to other people that Josh and I trusted.
After the first year we started inviting people using a simple rule: 75% of all invites will go to alumni. speakerconf alumni will already have existing relationships with other alumni, and they'll be more willing to share - due to their previous experiences at speakerconf. We always want new people and fresh ideas at speakerconf, but we don't want to lower the trust level by throwing in a larger group of people who haven't yet built strong relationships. We've experimented with inviting less alumni and never been happy with the results. For speakerconf 75% seems to be the magic number.
These days, Josh and I only invite new people to speakerconf based on alumni recommendations. Alumni recommendations are often for people from various backgrounds; which is perfect, as Josh and I prefer to have presenters with diverse experiences. I believe the key to embracing diversity while not compromising on trust is to focus on presenters that have mutual respect for each other despite their backgrounds.
Encourage relationship building
Every speakerconf begins with a meet & greet networking session. This session is usually at a hotel lounge area, and it's only purpose is for each of the speakers to get a chance to meet each other. Following the meet & greet, everyone is invited to an "unoffical" dinner. It's not required or covered by the conference, but it allows people to continue to get to know each other, if they like. Very rarely do any presenters skip this opening dinner.
During both the dinners and the open discussions we provide conference sponsored drinks - to get the honest discussions flowing. I'll be honest, when I'm stone cold sober I can be a bit shy. I get the impression that other speakers sometimes share this personality trait. The open discussions do often begin a bit timidly; however, after a round or two we quickly move to pulling no punches and diving head first into whatever interests us the most.
Off the record
At speakerconf, we don't even provide the option to record your talks. It would be great if we had some material that we could put on line for the rest of the community to benefit from, but we're not willing to sacrifice any level of honesty for the sake of information sharing. We've surveyed the presenters and they've unanimously agreed that they do not want their presentations to be recorded, and they would likely change what they said simply if a camera were present in the meeting room.
It's obvious, but we also remind everyone that if their presentation contains any sensitive information then they should begin by asking the audience not to repeat anything from the presentation. Also, at the beginning of every speakerconf we ask all the speakers to refrain from repeating (e.g. tweeting) any information without first consulting the source of the information.
Network
We don't wear nametags at speakerconf, and we don't go around the room and introduce ourselves. I personally hate nametags, and we found the introduction-go-around to be a bit dry and awkward. Instead, before every presenter speaks, Josh stands up and provides several facts about a person, and a single lie. It's up to the audience to decide which statements are which, though it's generally obvious due to the lie being the statement that caused everyone to laugh. It's fun, and turns the traditional awkward introduction into something you look forward to at the beginning of each presentation.
We don't officially organize seating for lunch or dinner at speakerconf, but we do encourage people to rotate who they sit with while they're dining. We found that the level of trust goes up greatly after you've taken the time to break bread with someone, and we want to encourage that trust building in anyway possible. Like I said, we don't organize anything specific here, we just lead by example; we try to pick our company for our next meal based on who we've spent the least amount of time with.
That's about all we do. There's nothing revolutionary about our methods; however, the result is an environment where trust goes a long way towards helping a presentation reach it's full potential.
... it's who you know
Josh and I don't tend to keep people we can't trust within our networks. Therefore, when we began inviting people to speakerconf we already knew we were assembling a group of people that could be honest with each other. I believe the speakers had mutual trust with Josh and I, and that trust was easily extended to other people that Josh and I trusted.
After the first year we started inviting people using a simple rule: 75% of all invites will go to alumni. speakerconf alumni will already have existing relationships with other alumni, and they'll be more willing to share - due to their previous experiences at speakerconf. We always want new people and fresh ideas at speakerconf, but we don't want to lower the trust level by throwing in a larger group of people who haven't yet built strong relationships. We've experimented with inviting less alumni and never been happy with the results. For speakerconf 75% seems to be the magic number.
These days, Josh and I only invite new people to speakerconf based on alumni recommendations. Alumni recommendations are often for people from various backgrounds; which is perfect, as Josh and I prefer to have presenters with diverse experiences. I believe the key to embracing diversity while not compromising on trust is to focus on presenters that have mutual respect for each other despite their backgrounds.
Encourage relationship building
Every speakerconf begins with a meet & greet networking session. This session is usually at a hotel lounge area, and it's only purpose is for each of the speakers to get a chance to meet each other. Following the meet & greet, everyone is invited to an "unoffical" dinner. It's not required or covered by the conference, but it allows people to continue to get to know each other, if they like. Very rarely do any presenters skip this opening dinner.
During both the dinners and the open discussions we provide conference sponsored drinks - to get the honest discussions flowing. I'll be honest, when I'm stone cold sober I can be a bit shy. I get the impression that other speakers sometimes share this personality trait. The open discussions do often begin a bit timidly; however, after a round or two we quickly move to pulling no punches and diving head first into whatever interests us the most.
Off the record
At speakerconf, we don't even provide the option to record your talks. It would be great if we had some material that we could put on line for the rest of the community to benefit from, but we're not willing to sacrifice any level of honesty for the sake of information sharing. We've surveyed the presenters and they've unanimously agreed that they do not want their presentations to be recorded, and they would likely change what they said simply if a camera were present in the meeting room.
It's obvious, but we also remind everyone that if their presentation contains any sensitive information then they should begin by asking the audience not to repeat anything from the presentation. Also, at the beginning of every speakerconf we ask all the speakers to refrain from repeating (e.g. tweeting) any information without first consulting the source of the information.
Network
We don't wear nametags at speakerconf, and we don't go around the room and introduce ourselves. I personally hate nametags, and we found the introduction-go-around to be a bit dry and awkward. Instead, before every presenter speaks, Josh stands up and provides several facts about a person, and a single lie. It's up to the audience to decide which statements are which, though it's generally obvious due to the lie being the statement that caused everyone to laugh. It's fun, and turns the traditional awkward introduction into something you look forward to at the beginning of each presentation.
We don't officially organize seating for lunch or dinner at speakerconf, but we do encourage people to rotate who they sit with while they're dining. We found that the level of trust goes up greatly after you've taken the time to break bread with someone, and we want to encourage that trust building in anyway possible. Like I said, we don't organize anything specific here, we just lead by example; we try to pick our company for our next meal based on who we've spent the least amount of time with.
That's about all we do. There's nothing revolutionary about our methods; however, the result is an environment where trust goes a long way towards helping a presentation reach it's full potential.
Wednesday, June 13, 2012
So, You Dropped Out of College
I was recently chatting to some friends about all the apprenticeship experiments going on and (name withheld to protect the innocent) lamented:
Okay, I didn't actually participate in an apprenticeship program that taught me Rails. However, I did drop out of college after gaining some experience programming, get a job building web applications, and I was laid off about a year later. Getting another job wasn't so hard, but it was hard to find a job that paid as well. It turns out, there's not a huge demand for people who don't have formal education or much experience, go figure.
While I was looking for a new job I noticed that there were significantly more jobs for people with certain skills. I'm sure it differs by location and time - in Jacksonville FL, around 2000, 75% of the jobs openings were looking for people with Microsoft .net skills. Sadly, I did not have .net skills. That was when I learned that I needed to have not just the skills necessary to do my job today, but also the skills necessary to land a new job tomorrow. Since I wasn't already in that situation, I had to settle for a job making .5 of my previous salary; however, my new job did allow me to learn .net.
I firmly believe: if you have less than 4 years of experience, you should always know what technology is in the highest demand for your area, and you should be proficient enough that you can do well in an interview. Perhaps your day to day job already teaches you the most highly sought after skills, fantastic, you should probably learn the 2nd most sought after skill. Don't wait until you're already looking for a job to try to learn a new technology. The truth is, learning something new will almost certainly help you with your current job as well, so everyone wins.
Whatever technology you choose will certainly have specific books that you should read; however, there are other books that will also help make up for the experience you (sadly, we) missed by not getting a Computer Science degree.
Refactoring was the first book I ever read that really opened my eyes to better ways to program. It's a pretty easy book to read, even for a beginner, and I can't recommend it enough. It's likely that you find that the most in-demand technology is Java or C#, and Refactoring will complement learning either of those languages. However, if you prefer, there's a Refactoring: Ruby Edition as well.
Once you've read refactoring, it's good to dig into Patterns of Enterprise Application Architecture (PofEAA). PofEAA contains patterns that are found all over the enterprise world (including ActiveRecord). You should read this book not because it is a bible, but because it shows you various solutions to commonly encountered problems. It gives you ideas about how other people are solving problems, and provides reference data that you can refer to if you encounter any of those issues in the future.
Those two books will demonstrate to potential employers that you're interested in building successful business applications; however, you'll also want to read a few books that diversify your experience and open your eyes to what can be done by using less mainstream techniques.
The wizard book and the dragon book sound like interesting fictional books, but are actually building blocks for your programming career. Both books are widely regarded as classics that any serious programmer should read. That said, they are not easy to digest. I'm not going to claim it will be fun, but you should push your way through both of these books - and then do it again a year later. These books can help shape your career in a positive way, especially the wizard book, perhaps more than any other text available.
Once you've pushed through both of those books, there are a few follow up options. If you preferred the wizard book, I would recommend following up with The Joy of Clojure or Learn You a Haskell For Great Good. You're unlikely to get a job using either technology, but both will broaden your horizons and also demonstrate to potential employers that you are deeply interested in increasing your programming capabilities. If you preferred the dragon book, I would move on to Domain Specific Languages. Domain Specific Languages is the definitive guide to DSL programming, and provides you with many examples of how to put DSLs to practical use within your applications.
Once you've made it through all (or most) of those books, you shouldn't have any problem finding a job that is both satisfying and also pays well.
So, what happens when they quit that first job (or worse, get laid-off) and their only skill is writing a Rails app?I know what happens. It happened to me.
Okay, I didn't actually participate in an apprenticeship program that taught me Rails. However, I did drop out of college after gaining some experience programming, get a job building web applications, and I was laid off about a year later. Getting another job wasn't so hard, but it was hard to find a job that paid as well. It turns out, there's not a huge demand for people who don't have formal education or much experience, go figure.
While I was looking for a new job I noticed that there were significantly more jobs for people with certain skills. I'm sure it differs by location and time - in Jacksonville FL, around 2000, 75% of the jobs openings were looking for people with Microsoft .net skills. Sadly, I did not have .net skills. That was when I learned that I needed to have not just the skills necessary to do my job today, but also the skills necessary to land a new job tomorrow. Since I wasn't already in that situation, I had to settle for a job making .5 of my previous salary; however, my new job did allow me to learn .net.
I firmly believe: if you have less than 4 years of experience, you should always know what technology is in the highest demand for your area, and you should be proficient enough that you can do well in an interview. Perhaps your day to day job already teaches you the most highly sought after skills, fantastic, you should probably learn the 2nd most sought after skill. Don't wait until you're already looking for a job to try to learn a new technology. The truth is, learning something new will almost certainly help you with your current job as well, so everyone wins.
note: searching hipster-programming-jobs.com to find out what's in demand is a selection bias failure. Use monster.com & dice.com. The goal is to appeal to as many companies as possible, not just the cool ones. You can focus on your dream job once you've got enough experience to ensure that your career doesn't suffer a failure to launch.
Whatever technology you choose will certainly have specific books that you should read; however, there are other books that will also help make up for the experience you (sadly, we) missed by not getting a Computer Science degree.
Refactoring was the first book I ever read that really opened my eyes to better ways to program. It's a pretty easy book to read, even for a beginner, and I can't recommend it enough. It's likely that you find that the most in-demand technology is Java or C#, and Refactoring will complement learning either of those languages. However, if you prefer, there's a Refactoring: Ruby Edition as well.
Once you've read refactoring, it's good to dig into Patterns of Enterprise Application Architecture (PofEAA). PofEAA contains patterns that are found all over the enterprise world (including ActiveRecord). You should read this book not because it is a bible, but because it shows you various solutions to commonly encountered problems. It gives you ideas about how other people are solving problems, and provides reference data that you can refer to if you encounter any of those issues in the future.
Those two books will demonstrate to potential employers that you're interested in building successful business applications; however, you'll also want to read a few books that diversify your experience and open your eyes to what can be done by using less mainstream techniques.
The wizard book and the dragon book sound like interesting fictional books, but are actually building blocks for your programming career. Both books are widely regarded as classics that any serious programmer should read. That said, they are not easy to digest. I'm not going to claim it will be fun, but you should push your way through both of these books - and then do it again a year later. These books can help shape your career in a positive way, especially the wizard book, perhaps more than any other text available.
Once you've pushed through both of those books, there are a few follow up options. If you preferred the wizard book, I would recommend following up with The Joy of Clojure or Learn You a Haskell For Great Good. You're unlikely to get a job using either technology, but both will broaden your horizons and also demonstrate to potential employers that you are deeply interested in increasing your programming capabilities. If you preferred the dragon book, I would move on to Domain Specific Languages. Domain Specific Languages is the definitive guide to DSL programming, and provides you with many examples of how to put DSLs to practical use within your applications.
Once you've made it through all (or most) of those books, you shouldn't have any problem finding a job that is both satisfying and also pays well.
Subscribe to:
Comments (Atom)