When testing functions that reference some state (atom, ref, or agent), it's nice to be able to quickly replace the value of the state in the context of the test. When your function only interacts with one piece of state, a simple call to with-redefs will do the trick. However, there are times when the function that you're calling updates many different pieces of state, and you'd like to be able to redef all of them with one call. The expectations testing framework (v 1.4.16 and above) provides you the ability to redef all atoms, refs, and agents in a namespace with one call to redef-state.
(this same feature existed in expectation.scenarios as 'localize-state')
Let's take a look at the following contrived namespace
In the above namespace we have two atoms that are both updated when you process an update. Testing that the atoms are updated is fairly simple, which the tests below demonstrate.
Unfortunately, these tests will not both pass, as they both update the same atom. We could clean up at the end of each test, but it's usually cleaner to simply redef the atoms in the context of the test. The tests below use with-redefs to ensure that the state is only manipulated in the context of the tests.
At this point the tests all pass. This solution works fine, but expectations gives you the ability to trim a bit of code and simply specify the namespace instead. The following tests specify the namespace and let expectations take care of the rest.
That's it. Now all atoms, refs, and agents that are defined in the 'blog' namespace will be redefined within the context of the (redef-state) call. It's also important to note that redef-state can take as many namespaces as you'd like to specify in the first arg vector.
Wednesday, October 31, 2012
Tuesday, October 09, 2012
Java: Add A Println To A 3rd-Party Class Using IntelliJ's Debugger
When I'm working with 3rd party Java code (e.g. joda.time.DateTime) and I want to inspect values that are created within that code, I generally set a breakpoint in IntelliJ and take a look around. This works the vast majority of the time; however, there are times when this approach isn't an option. For example, if stopping your application changes the state of what you're looking at, or if stopping the application causes your breakpoint to fire repeatedly in irrelevant situations, then you'll probably want another solution for looking around 3rd party code.
It turns out, IntelliJ gives you the ability to inspect values within 3rd party code - without needing to stop the application at a breakpoint. The following code uses the 3rd party library joda-time, and is simply printing the current time to the console.
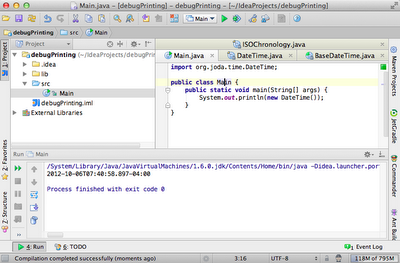
note: this code could simply use a breakpoint if you wanted to inspect some 3rd party code, but I didn't see the value in creating a more complicated example.
In the example, we're calling the constructor of DateTime, which simply delegates to the BaseDateTime constructor, which can be seen in the following screenshot.

So, we're looking at joda-time code that we can't edit, but our task is to get the value of DateTimeUtils.currentTimeMillis() and ISOChronology.getInstance() without stopping the application. The solution is to add a breakpoint, but do a bit of customization.
In the following screenshot we've added a breakpoint to the line that contains the values we're interested in and we're right clicking on the breakpoint, which will allow us to edit the properties of the breakpoint.
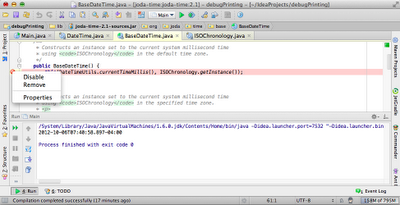
When we open the properties of a breakpoint, they will look something like the following screenshot.
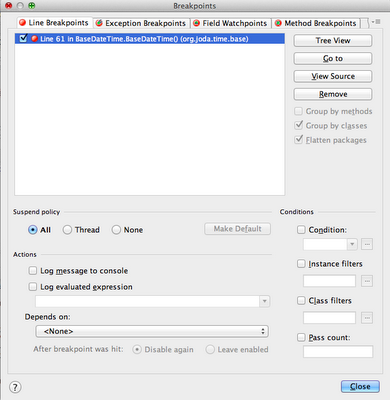
In the properties window you'll want to set Suspend policy to 'None', and you'll want to set something in Log evaluated expression. In my properties window I've set the following expression:

At that point you close the properties pop-up and run your app once again (in Debug mode).

As you can see from the output, both the millis and the ISOChronology were printed to the console, and the application processing was never broken (it simply ended as expected).
That's it - now you can println in code you don't own to your heart's content.
It turns out, IntelliJ gives you the ability to inspect values within 3rd party code - without needing to stop the application at a breakpoint. The following code uses the 3rd party library joda-time, and is simply printing the current time to the console.

note: this code could simply use a breakpoint if you wanted to inspect some 3rd party code, but I didn't see the value in creating a more complicated example.
In the example, we're calling the constructor of DateTime, which simply delegates to the BaseDateTime constructor, which can be seen in the following screenshot.

So, we're looking at joda-time code that we can't edit, but our task is to get the value of DateTimeUtils.currentTimeMillis() and ISOChronology.getInstance() without stopping the application. The solution is to add a breakpoint, but do a bit of customization.
In the following screenshot we've added a breakpoint to the line that contains the values we're interested in and we're right clicking on the breakpoint, which will allow us to edit the properties of the breakpoint.

When we open the properties of a breakpoint, they will look something like the following screenshot.

In the properties window you'll want to set Suspend policy to 'None', and you'll want to set something in Log evaluated expression. In my properties window I've set the following expression:
System.out.println(DateTimeUtils.currentTimeMillis() + ", " + ISOChronology.getInstance()); - though, you can't see the full snippet in the screenshot.

At that point you close the properties pop-up and run your app once again (in Debug mode).

As you can see from the output, both the millis and the ISOChronology were printed to the console, and the application processing was never broken (it simply ended as expected).
That's it - now you can println in code you don't own to your heart's content.
Wednesday, October 03, 2012
clojure: lein tar
A co-worker recently asked how I package and deploy my clojure code. There's nothing special about the code, but I'm making it available here for anyone who wants to cut and paste. Deploy is the easy part - scp a tar to the prod box. Building the tar is very easy as well. I've run this on a few different linux distros without issue, but YMMV. Without further ado.
I'm sure there are easier ways, and I know I could do it programically - but this works and is easy to maintain. That's good enough for me.
I'm sure there are easier ways, and I know I could do it programically - but this works and is easy to maintain. That's good enough for me.
Tuesday, October 02, 2012
Clojure: Avoiding Anonymous Functions

Next, I went through several of the exercises on 4clojure.org and it opened my eyes to the sheer number of functions that I should have, but still didn't know. 4clojure.org helped me learn how to use many of the functions from the standard lib, but it also taught me a greater lesson: any data transformation I want to do can likely either be accomplished with a single function of clojure.core or by combining a few functions from clojure.core.
The following code has an example input and shows the desired output.
There are many ways to solve this problem, but when I began with Clojure I solved it with a reduce. In general, anytime I was transforming a seq to a map, I thought reduce was the right choice. The following example shows how to transform the data using a reduce
That works perfectly well and it's not a lot of code, but it's custom code. You can't know what the input is, look at the reduce, and know what the output is. You have to jump in the source to see what the transformation actually is.
You can solve this problem with an anonymous function, as the example below shows.
This solution isn't much code, but it's doing several things and requiring you to keep many things on your mental stack at the same time - what does the element look like, destructuring, the form of the result, the initial value, etc. It's not that tough to write, but it can be a bit tough to read when you come back to it 6 months later. Below is another solution, using only functions defined in clojure.core.
The above solution is more characters, but I consider it to be superior for two reasons:
- Only clojure.core functions are used, so I am able to read the code without having to look elsewhere for implementation or documentation (and maintainers should be able to do the same).
- The transformation happens in distinct and easy to understand steps.
If the learning opportunity did not exist, I may feel differently; however, I currently feel much more comfortable with update-in than I do with using juxt, and to a lesser extent (partial apply hash-map) & (apply merge concat). If you found the solution I prefer harder to follow, then I suspect you may be in the same boat as me. If you were easily able to read and follow both solutions, it probably makes sense for you to simply do what you prefer. However, if you choose to define your own function I do believe you're leaving behind something that's harder to digest than a string of distinct steps that only use functions found in clojure.core.
Regardless of language, I believe that you should know the standard library inside and out. Time and time again (in Clojure) I've solved a problem with an anonymous function, only to later find that the standard library already defined exactly what I needed. A few examples from memory: find (select-keys with 1 key), keep (filter + remove nil?), map-indexed (map f coll (range)), mapcat (concat (map)). After making this mistake enough times, I devised a plan to avoid this situation in the future while also forcing myself to become more familiar with the standard library.
The plan is simple: when transforming data, don't use (fn) or #(), and only define a function when it cannot be done with -> or ->> and clojure.core.
My preferred solution (above) is a simple example of using threading and clojure.core to solve a problem without #() or (fn). This works for 90% of the transformation problems I encounter; however, there are times that I need to define a function. For example, I recently needed to take an initial value, pass it to reduce, then pass the result of the reduce as the initial value to another reduce. The initial value is the 2nd of reduce's 3 args, thus it cannot easily be threaded. In that situation, I find it appropriate to simply define my own function. Still, at least 90% of the time I can find a solution by combining existing clojure.core functions (often by using comp, juxt, or partial).
Here's another simple example: Given a list of maps, filter maps where :current-city is "new york"
Once you've made this step, you may start asking yourself: am I doing something unique, or am I doing something that's common enough to be somewhere in the standard library. More often than I expected, the answer is - yes, there's already a fn in the standard library. In this case, we can use clojure.set/join to join on the current city, thus removing our undesired data.
Asking the question, "this doesn't seem unique - shouldn't there be a fn in the standard library that does this?", is what led me to clojure.set/project, find and so many other functions. Now, when I look through old code, I find myself shaking my head and wishing I'd started down this path even earlier. Clojure makes it easy to define your own functions that quickly solve problems, but using what's already in clojure.core makes your code significantly easier for others to follow - learning the standard library inside and out is worth the effort in the long term.
Subscribe to:
Posts (Atom)